javase
编程语法及规则与规范
编辑阶段的整体注意点
见名知意、注意缩进、成对编程;
严格区分大小写,英文大写字母与小写字母意义不一样;
都是英文标点符号;
–> 经典错误:”非法字符”:’\uff09’ –> 使用了中文的标点符号;
main方法写法固定,是程序的入口,能被虚拟机识别并执行。
关于定义类的注意点?
使用public修饰的类,该类的名字必须和源文件名字保持一致,否则就会编译错误;
在源文件中,我们可以使用class来定义任意多个类,编译后就会生成任意多个字节码文件。
–> 编译后,没有类都会生成一个字节码文件,并且字节码文件名字就是类名。
在源文件中,我们可以定义多个类,但是最多只能有一个类使用public修饰(0或1)。
注释
- 单行注释
- 快捷键:ctrl + /
- 语法://
- 多行注释
- 快捷键:ctrl + shift + /
- 语法:/* 注释内容 */
- 文档注释
- 语法:/** 注释内容 */
常见的转义字符
- \t –> 制表符。作用:显示多个空格,并且还有对齐的功能;
- \n –> 换行符。作用:具有换行功能。
- \“,编译时,把它当成一个整体,不作为字符串结束的标记;运行时,会忽略反斜杠,只会展示出一个双引号。
- \‘,编译时会把它当成一个整体,运行时只会展示出一个单引号。
关于字符的使用
方式一:把字符放在字符串内部使用!
- System.out.println(“hello\tworld”);
方式二:把字符串单独使用,然后再使用+来拼接。
- System.out.println(“hello” + ‘\t’ + “world”);
注意:
- int类型和char类型做“+”运算,则做的是“加法操作”。
- String类型和char类型做“+”运算,则做的是“连接符操作”。
关于Unicode值得补充
- 因为java语言默认采用Unicode编码表,因此每个”字符”都对应一个Unicode值,其中一个Unicode值我们必须掌握
- ‘\u0000’代表的是空格字符
理解编译和反编译
编译:把源文件编译为字节码文件,也就是把”*.java”文件编译为”.class”文件
反编译:把字节码文件编译为源文件。
反编译的实现方式:
方式一:提供javap.exe来实现
- 实现:在字节码文件所在目录中,我们通过javap.exe来实现反编译,例如:javap HelloWorld04
- 优点:能看到编译时期默认做的操作,例如能看到编译时期默认提供的无参构造方法。
- 缺点:反编译之后,我们无法看到方法内部的具体实现,也就是看不到方法体。
方法二:通过jd-gui.exe来实现
- 实现:打开jd-gui.exe程序,然后把需要反编译的字节码文件拖拽进入jd-gui.exe程序中即可。
- 优点:反编译之后,我们能够看到方法内部的具体实现,也就是能看到方法体。
- 缺点:不能看到编译时期默认做的操作,例如无法看到编译时期默认提供的无参构造方法。
方法一与方法二可以看作是互补的。
文件存储的的单位
实际开发中,我们把字节称之为文件存储的最小单位。
开发中,字节有两种表示方式,分别为:
无符号表示
(只能表示正数,不能表示负数)
- 1个字节无符号表示的数值范围在【0,2^8-1】之间,也就是表示范围在【0,255】之间。
- 作用:基本数据类型中,char类型采用的就是无符号来表示。
有符号表示
(不但能表示正数,还能表示负数)
- 1个字节有符号表示的数值范围在[-2^ 7,2^7-1]之间,也就是表示范围在[-128,127]之间。
- 作用:基本数据类型中,byte、short、int和long类型采用的就是有符号来表示。
常见的文件存储单位及其换算公式
- 1KB = 1024Byte
- 1MB = 1024KB
- 1GB = 1024MB
问题
:长度单位的换算使用的是1000,为什么文件存储单位换算使用的是1024呢?
- 答:二进制早期有电信号开关演变而来,也就是意味着文件存储的换算肯定使用的是2的多少次方,而2的10次方结果就是1024,也就是2^10是最接近于1000的整数,因此就使用了1024来作为文件存储的换算值。
标识符的作用
- 标识符就是给类名、方法名、变量名、常量名和包名命名的规则。
标识符的规则
- 必须由数字、字母、下划线和&组成,并且开头不能是数字。
- 标识符不能是关键字或保留字,因为关键字和保留字是给编程语言使用。
- 在java语言中,对于标识符的长度没有任何限制,也就是标识符可以任意长。
- 补充:java语言默认采用Unicode编码表,而Unicode编码表几乎包含了全世界所有的文字。
- 注意:此处的“字母”我们应该广义地去理解,也就是此处“字母”可以是“英文”,也可以是“中文”。
- 建议:给标识符进行命名的时候,我们不建议使用“中文汉字”来进行命名。
命名规范的讲解
明确:命名的时候不建议使用”中文汉字“,并且还必须做到“见名知意”的要求。
类名:必须遵守“大驼峰”的命名规范,大驼峰:每个单词首字母都大写。
- 例如:HelloWorld、VariableDemo
方法名、变量名:必须遵守“小驼峰”的命名规则,小驼峰:第一个单词首字符小写,从第二个单词起首字母都大写。
- 例如:userName、maxValue
常量名:必须遵守“字母全部大写,多个单词之间以下划线连接”的命名规范。
- 例如:USER、NAME
包名:必须遵守“单词全部小写,多个单词之间以 ‘.’ 连接,并且必须做到顶级域名倒着写”的命名规范。
数据类型
数据类型的分类
基本数据类型【八大基本数据类型】
整数型:byte、short、int、long
浮点数:float、double
布尔型:boolean
字符型:char
引用数据类型
- 数组、字符串、类和接口等等
整数型(有符号表示)
byte,占用1个字节,则表示范围在[-2^7, 2^7-1]之间,–> [-128, 127]。
short, 占用2个字节,[-2^15, 2^15-1], –> [-32768,32767]。
int, 占用4个字节,[-2^31, 2^31-1], –> 大概在正负21亿之间。
long, 占用8个字节,[-2^63, 2^63]。
注意:
占用的字节数越大,则表示的数值范围也就越大,开发中我们需要根据存储数值的大小来选择合适的数据类型。
–> 存储的数值大小不能超出其数据类型的表示范围,否则就会编译错误。
–> 实际开发中,byte和short几乎不会使用。存储较小的数值使用int,存储较大的数值使用long。
开发中,只能使用八进制、十进制、十六进制来表示整数,不能“直接”使用二进制来表示整数。
- int num1 = 017:八进制;
- int num1 = 23:十进制;
- int num1 = 0x2B:十六进制;
整数固定值常量默认为int类型,在整数固定值常量的末尾添加”L”【推荐】或”l”,则该常量就变为Long类型。
浮点型(小数)
- float,占用4个字节,我们称之为“单精度类型”,理论上能精确到小数点后7位。
- double,占用8个字节,我们称之为“双精度类型”,理论上精确度是float的两倍。
注意:
占用的字节数越大,则表示小数的精确度就越高,开发中我们建议使用double类型。
–> 开发中,float类型很少使用,因为精确度太低,而double类型很常用。
小数的表示方式有:1)生活中的表示小数;2)使用科学计数法来表示小数。
–> 3.14E3,等效于:3140.0 –> “乘以10的3次方”
–> 3.14E-3,等效于:0.00314 –> “除以10的3次方”
注意:使用科学计数法来表示小数的时候,此处的英文字母不区分大小写(E或e)。
因为小数存储的区别,因此不建议使用小数来做特别精确的运算,因为得到结果可能不精确。
–> double sum = 0.001 + 0.0002; 理论结果是:0.0003 实际结果:0.000300000000000000000003
小数固定值常量默认为double类型,在小数固定值常量末尾添加”F”【推荐】或”f”,则该常量就变为:float类型。
浮点型占用的字节数,强调的是存储”小数部分”占用的字节数,并不是强调存储”整数部分”占用的字节数。
–> float类型存储”整数部分占用8个字节”,存储”小数部分占用4个字节”,总计至少占用12个字节。【底层(科学计数法)】
布尔型(boolean)
明确:布尔类型的固定值常量只有true和false,并且true和false都是关键字。
–> true:表示为真或条件成立
–> flase:表示为假或条件不成立
使用场合:常用于条件判断,条件成立则返回true,条件不成立则返回false。
面试题:请问boolean类型占用几个字节?
–> 在java规范中,没有明确boolean类型占用几个字节。我个人觉得boolean类型占用x个字节,并说出理由!
字符型(char,无符号表示)
- 明确:字符型占用2个字节数,表示的数值范围在[0,2^16-1]之间,也就是表示范围在[0,65535]之间。
- 注意:使用单引号包裹的一个字符串,我们就称之为字符固定值常量。
字符串类型?
明确:字符串类型的名字叫做String类型,并且String类型属于”引用数据类型”。
注意:使用双引号包裹的任意多个字符,我们就称为“字符串固定值常量”。
–> 双引号包裹的0个字符,我们就称之为”空字符串”。
关于”+”的作用
- 表示正数。eg:int num = +8;
- 加法运算,要求两个操作数都必须是数值型。eg:int sum = 5 + 8;
- 连接符,要求其中一个操作数必须是字符串类型。eg:”hello” + true;
- 结论:字符串的连接符操作,则运算完毕后返回的结果肯定属于String类型。
数据类型的转换
为什么需要学习数据类型的转换?
- 因为java是强类型的语言,因此参与“赋值运算”和“算数运算”的时候,要求参与运算的数据类型必须保持一致,否则就需要做数据类型转换。
基本数据类型转换的方式有哪些?
- 隐式类型转换(自动)
- 强制类型转换(手动)
哪些基本数据类型可以相互转换?
- 除了boolean类型外,其余的基本数据类型都可以相互转换。
隐式类型转换(自动)
- 原则:低字节向高字节自动提升。
- byte –> short –> int –> long –> float –> double
- char –> int
赋值运算:
原则:低字节向高字节自动提升。
特例:把int类型的常量,赋值给byte、short和char类型的变量或final修饰的常量时,则就是属于隐式类型转换的特例。只需赋值的数据没有超出其数据类型的表示范围即可。
–> 赋值的数据应该是什么?赋值的数据应该是int类型的常量!
–> 赋值数据的大小是什么?赋值数据的大小不能超出其数据类型的表示范围。
算术运算
原则:两个操作数做运算,如果其中一个操作数为double类型,则另外一个操作数也会隐式转化为double类型;否则,如果其中一个操作数为float类型,则另外一个操作数也会隐式转化为float类型,最终计算结果就是float类型;否则,如果其中一个操作数为long类型,则另外一个操作数也会隐式转化为long类型,最终计算结果就是long类型;否则,这两个操作数都会隐式转化为int类型,最终计算的结果就是int类型。
强制类型转换
当隐式类型转换无法解决问题时,我们要采用强制类型转换。
语法:目标类型 变量 = (目标类型) 数据;
eg: int num = (int) 3.14; –> 可以用来小数取整。【一、想要的精度丢失】
底层:只保留低位字节的二进制,高位字节的二进制就丢弃。
注意:使用强制类型转换的时候,可能就丢失精度,使用的时候切记。【二、不想要的精度丢失】
–> int num = (int) 3.14; 只保留了整数位,丢失了小数位。
强制类型转换后,被强制转换的变量还是原来的数据类型。
eg: int num; byte num1 = (int) num; –> num (int类型)
使用强制类型转换的时候,我们必须明确强制转换数据的范围,否则得到的结果就不准确。
运算符
赋值运算符
- “=”,作用:把等号右边表达式的结果赋值给等号左边的变量或final修饰的常量保存。
算法运算符的分类
一元运算符(只需要一个操作数参与运算)
包含:++、–
二元运算符(需要两个操作数来参与运算)
包含:+ 、-、*、/、%
+:表示正数,加法运算,连接符操作;
-:表示负数,减法运算;
*:乘法运算
/:除法运算
%:取模运算或取余运算
–> 作用:获得两个整数相除的余数
eg:0 % 3 = 0 –> 注意:0能被任何数整除。
1 % 3 = 1
注意:”除法运算”是获得两个整数相除的”整数位结果”,”取模运算”是获得两个整数相除的”余数”。
使用场合:
判断m能否被n整除,如果m%n的结果为0,则意味着m能被n整除;如果m%n的结果不为0,则意味着m不能被n整除。
“任意数 % m”,则得到的结果肯定在[0,m - 1]之间,例如:”任何数 % 3”,则得到的结果肯定是在[0, 2]之间。
除法运算符的注意事项
- 在java语言中,两个整数做除法运算,则得到的结果肯定为整数。
- 在java语言中,做除法运算的时候,分母不能为0,否则就会抛出算数异常(ArithmeticException)。
比较运算的概述
明确:比较运算符返回的结果肯定是boolean类型。
如果条件成立,则返回true;如果条件不成立,则返回false。
包含:> 、>=、<=、==、!=
==(等于),判断左右两边的结果是否相等。
–> 如果左右两边属于“基本数据类型”,则比较左右两边的“数据值”是否相等(掌握)。
–> 如果左右两边属于“引用数据类型”,则比较左右两边的“地址值”是否相等(了解)。
!=(不等于),判断左右两边的结果是否不相等。
–> 如果左右两边属于“基本数据类型”,则比较左右两边的“数据值”是否不想等(掌握)。
–> 如果左右两边属于“引用数据类型”,则比较左右两边的“地址值”是否不相等(了解)。
注意点:
- 比较运算符是一个整体,中间不允许条件空格!
- 注意区分“=”和“”的区别,“=”属于赋值运算符,“”属于比较运算符。
逻辑运算符的概述
明确:参与逻辑运算的数据必须是boolean类型,并且逻辑运算符返回的结果肯定是boolean类型。
包含:&、|、^、&&、||、!
&(与运算符),属于二元运算符
–> 结论:只要两边都为true,则结果就是true。
只要有一边为false,则结果就是false。
辅助记忆:小明“与”小红来一趟办公室。
|(或运算符),属于二元运算符
–> 结论:只要两边都为false,则结果就是false。
只要有一边为true,则结果就是true。
辅助记忆:小明“或”小红来一趟办公室。
^:异或运算,相同为false,不同为true。
———————–以上三个开发中不常用,但是结论很重要———————-
———————–以下三个开发中常用,并且结论也很重要———————-
&&(短路与),属于二元运算符
结论1:&和&&的执行结果一样。
结论2:&&当左侧表达式为false时,右边不执行,结果直接原样返回左侧结果为false。
&&当左侧表达式为true时,右边执行,结果直接原样返回右侧结果。
||(短路或),属于二元运算符
结论1:|和||的执行结果一模一样;
结论2:如果左侧表达式的结果为true,则右边表达式肯定不会执行,并且原样返回左侧表达式的结果(true)。
如果左侧表达式的结果为false,则右侧表达式肯定会去执行,并且原样返回右侧表达式的结果(true|false)。
!(非运算),属于一元运算符。
使用场合:
- 如果两个条件必须成立才能满足需求,则这两个条件之间使用“&&”来组织关系;
- 如果两个条件其中一个成立既能满足需求,则这两个条件之间使用”||”来组织关系。
位运算(了解,建议掌握)
明确:参与位运算的数据应该是整数型,并且位运算返回的结果也是整数。
包含:&、|、^、~、<<、>>、>>>
&(与位运算),属于二元运算符
结论:位都为1,则结果就是1;位有一个为0,则结果就是0
使用场合:学习HashMap集合的时候,验证为啥底层的数组空间长度必须为2的整数次幂。
|(或为运算),属于二元运算符
结论:位都为0,则结果就是0;位有一个为1,则结果就是1
^(异或位运算),属于二元运算符
结论:位相同,则为0;位不同,则为1
特点:对m连续异或n两次,得到的结果依旧为m
–> m^n ^ n 的结果为m,n^m ^n的结果为m,n ^ n ^ m的结果为m
使用场合:
- 使用异或位运算,我们可以实现对数据的”加密”和”解密”操作。
- 加密:对需要加密的数据异或m,则就得到了加密后的结果。
- 解密:对加密后的数据继续异或m,则就得到了解密后的结果。
- 使用异或位运算,用于交换两个变量的值。
- 优点:效率非常高;
- 缺点:复杂、不好理解。
~(非位运算符),属于一元运算符
结论:二进制位取反的含义。0取反的结果就是1,1取反的结果就是0。
<< (左移位运算)
结论:对m左移n位,则等效于:m * 2n
–> 此处m可以是正数,也可以是负数!
特点:左移运算之后,则低位永远补0即可。
使用场合:对m做乘以2的操作,则最高效的方式为:m << 1
(>>右移位运算)
结论:对m右移n位,则等效于:m/2n
–> 此处m必须是正数,不能为负数!
特点:正数右移,则高位补0;负数右移,则高位补1
使用场合:对m做除以2的操作,则最高效的方式为:m>>1
–> 此处m必须有正好,不能为负数!
(>>>无符号右移)
- 无论对正数还是负数做无符号右移的操作,则高位永远补0即可。
三目运算符
语法:数据类型 变量名 = 条件表达式?表达式1 : 表达式2;
执行:如果”条件表达式”的结果为true,则执行”表达式1“,也就是”把表达式1*的结果赋值给等号左边的变量来保存。
如果”条件表达式“的结果flase,则执行“表达式2”,也就是把“表达式2”的结果赋值给等号左边的变量来保存。
注意:if…else选择结构在某些情况下可以被三目运算符代替,毕竟这两者都是做的“二选一”的操作。
循环选择结构
顺序执行
- 代码自上而下,依次执行。
选择结构
if选择结构
- if单选结构
- 概述:if(条件表达式){ //当“条件表达式”的结果为true,则执行此处的代码。}
- 注意:
- 此处的“条件表达式”返回的结果必须时Boolean型。
- if选择结构依旧包含在顺序执行中,也就是顺序执行中包含了选择执行。
- if双选结构
- if多选结构
- 在完整的if多选结构中,有且只能执行一个大括号中的代码(多选一)。
- if,最前面,有且只能有一个(1)
- else if,中间位置,可以有任意多个(0,1,2,…,n)
- else,最后面,最多只能有一个(0或1)
- if选择结构的总结
- 如果if选择结构中只有一行代码,则我们还可以省略大括号!省略大括号之后,则编译时会默认添加一个大括号,用于包裹if结构中的第一行代码。
- 建议:对于初学者而言,不建议省略if选择结构中的大括号,省略大括号之后可能会带来额外的问题。
- if单选结构
switch选择结构
关于switch关键字的注意点:
- 此处“表达式”的结果必须是byte、short、int、char、String和枚举(后面学习)类型 ,别的类型都会编译错误!
- “表达式”的结果不能是boolean类型,因此switch选择结构就不能对布尔类型的数据进行匹配!
关于case关键字
case关键字后面必须是“常量”,不能为“变量”,从而保证匹配的安全性!
在switch选择结构中,case后面不允许有多个“相同的”常量值,否则就会编译错误!
在此处“表达式”结果的类型和case后面“常量值”的类型必须保持一致,否则就会编译错误!
–> 此处的数据类型必须“保持一致”,包含了“隐式类型转换”之后能保持一致。
–> 因为“表达式”结果不支持boolean类型,因此case后面就不能为boolean类型的数据,也就是不支持区间判断。
关于break关键字的注意点:
一旦执行break关键字,则就会跳出switch选择结构,执行switch选择结构之后代码。
在switch选择结构中,我们可以省略break关键字,省略break关键字之后,则就会发生“穿透”,直到遇到下一个break才会结束“穿透”。
关于default关键字的注意点:
- 当switch选择结构中的所有case都无法匹配成功,则那么才会去执行default中的代码,此处的default类似于if选择结构中的else代码块。
- 在switch选择结构中,虽然可以省略default关键字,但是我们不建议省略,除非case都匹配所有的问题。
强调:在某个case中定义的变量,则该变量就只能在当前作用域中使用,不能在别的case中使用!
循环结构
- for循环
- for循环结构,我们也称为“带名字的代码块”或“带条件的代码块”,因此在“循环体”中定义的变量不能再循环之外使用。
- 在循环体定义的变量,每次执行循环体该变量都“出生”,每次循环体执行完毕该变量都“死亡”。
- 问题:想要在循环体中,每次操作的都是同一个变量,则该变量应该定义在哪里?–> 必须定义在循环之前!
- “循环条件表达式”返回的结果必须是boolean类型,但是“循环初始化表达式”和“循环后的操作表达式”没有特殊要求
- while循环
- while循环结构:先进行判断,若返回值为true则进行循环,反之则跳过循环
- do…while循环
- do…while循环:先将方法体执行一遍,然后进行判断,若返回值为true则进入循环,反之则跳过循环
方法的调用及内存分析
调用方法的内存分析(重点)
- 栈内存的特点?
- 栈内存具备“先进后出,后进先出”的特点,类似于生活中的“子弹夹”。
- 调用方法的内存分析?
- 调用方法的时候,则自动就会在栈内中开辟一个“栈帧”,用于执行该方法体中的代码。–>入栈操作
- 方法调用完毕的内存分析
- 在方法体中一旦执行“return”关键字,则就证明方法调用完毕,那么调用方法时所开辟的“栈帧”就会被摧毁。–> 弹栈操作
- 问题:调用方法的时候,实参num1和num2与形参num1和num2是否有关系?
- 答案:此处的“实参”和”形参”没有任何关系,仅仅是”名字”相同而已。
方法的使用(重点)
方法的使用原则
- 先声明,后调用。
方法声明的难点
- 明确1:完成该功能,是否需要返回值。–> 返回值类型
- 明确2:完成该功能,是否需要外部参数参与方法内部的运算。 –> 形参列表
方法的分类
无参无返回值方法
需求:在方法中输出“hello world”。
分析:完成该功能,无需返回值,因此返回值类型为void。
完成该功能,无需外部参数参与方法内部运算,因此没有形参。
无参有返回值方法
需求:调用方法获得常量3+4的和。
分析:完成该功能,需要返回值,因此返回值类型为int。
完成该功能,无需外部参数参与方法内部的运算,因此没有参数
有参无返回值方法
需求:在方法中输出指定两个int数据之和。
分析:完成该功能,无需返回值,因此返回值类型为void。
完成该功能,需要外部参数参与内部的运算,也就是需要两个int类型的形参。
有参有返回值方法
需求:调用方法获得指定两个double数据之和。
分析:完成该功能,需要返回值,因此返回值类型为double。
完成该功能,需要外部参数参与方法内部的运算,也就是需要两个double类型的形参。
方法的重载(overload)重点
方法重载的定义
同一个类中,具有相同的方法名,但是参数个数不同或参数类型不同,这就构成了方法的重载!
核心:两同,两不同
–> 两同:同一个类中,具有同名的方法。
–>两不同:参数个数不同,参数个数不同 或 参数类型不同。
方法重载的特点
- 修饰符不同,没有构成方法重载;
- 形参名字不同,没有构成方法重载;
- 返回值类型不同,没有构成方法重载。
方法重载的好处
- 官方:方法重载的出现,使其同一个类中允许定义多个同名的方法,从而避免了方法名被污染。
- 通俗:学习方法重载之后,如果同一个类中多个同名的方法发生了编译错误,则首先考虑这些方法是否满足方法重载!
重载方法的调用
- 调用重载方法的时候,会根据实参的“个数”和“类型”来选择调用合适的方法。
目前已经用过的重载方法有哪些?
- print()、println()等等
- 问题:通过IDEA工具,如何查看底层的API源码?
- 实现:按下Ctrl键,然后鼠标左键单击即可。
调用方法时,实参传递给形参的过程(超级重点)
- 调用方法时,基本数据类型的传递
- 结论:”基本数据类型”的传递,属于”数据值”的传递。
- 解释:”实参”赋值给”形参”之后,则”实参”和”形参”就没有任何联系了,我们在方法中修改”形参”的值,则”实参”的值不会改变。
- 调用方法时,引用数据类型的传递
- 结论:”引用数据类型”的传递,属于”地址值”的传递。
- 解释:”实参”赋值给”形参”之后,则”实参”和”形参”保存的地址值就相同,也就意味着”实参”和”形参”指向了同一块存储空间,我们在方法中修改”形参”指向存储空间的数据,则”实参”指向该存储空间的数据也被修改了。
数组
数组的声明
- 数组就是一个存储“相同数据类型”的“有序”集合(容器)。
- 明确:所谓数组的声明,指的就是给数组取一个名字,类似于变量的声明。
- 语法1:数据类型[] 数组名;
- 语法2:数据类型 数组名[];
- 注意:开发中,建议使用“语法1”来声明数组,因为“数据类型[]”代表的是“数组类型”。
数组的创建
明确:所谓数组的创建,指的就是在内存中为数组开辟存储空间。
方式一:动态创建数组(仅仅在内存中开辟存储空间,但没有给数组元素指定赋值)
- 语法:数据类型[] 数组名 = new 数据类型[空间长度];
方式二:静态创建数组(不但在内存中开辟存储空间,并且还给数组元素指定赋值)
语法1:数据类型[] 数组名 = {数据1,数据2,数据3,…};
语法2:数据类型[] 数组名 = new 数据类型[]{数据1,数据2,数据3,…};
操作数组元素
明确:想要操作数组元素,则必须通过“索引”来实现,因为通过“索引”就能找到元素对应的存储空间,然后就能做出“赋值”和“取值”的操作。
数组的注意点
数组存储的是相同数据类型的元素,则意味着每个元素占用的字节数相同。
数组是一块连续的存储空间,则意味着相邻两个元素的存储空间是紧挨着的。
创建数组的时候,我们必须明确数组的空间长度,并且数组一旦创建成功,则数组的空间长度就不能改变了。
给数组元素赋值的时候,赋值“元素的类型”必须和“声明数组的数据类型”保持一致,否则就会编译错误!
int[] arr = new int[5]; arr[0] = 11; //没问题 arr[1] = "abc"; //编译错误声明数组的时候,我们可以使用“基本数据类型”来声明数组,也可以使用“引用数据类型”来声明数组。
int[] arr1; //基本数据类型 String[] arr2; //引用数据类型通过索引来操作数组元素的时候,操作的索引值必须合法,如果索引值不合法就会抛出数组索引越界异常。
明确:数组索引的合法取值范围在[0,数组长度-1]之间,如果索引越界就会抛出数组索引越界异常(ArrayIndexOutOfBoundsException)。
数组属性
- 明确:基本数据类型没有属性和方法,但是引用数据类型有属性和方法。
- 强调:通过数组的“length”属性,我们可以动态的获得数组的空间长度。
数组元素的默认值
明确:通过“动态创建数组”的方式,则数组中每个元素都有默认值,并且元素的默认值规则如下:
- 整数型(byte、short、int和long)数组元素的默认值为:0
- 浮点型(float和double)数组元素的默认值为:0.0
- 布尔型(boolean)数组元素的默认值为:false
- 字符型(char)数组元素默认值为:’\u0000’ –> 代表空格字符
- 引用数据类型(数组、字符串、类和接口)数组元素的默认值为:Null –> 此处是null关键字,代表的是空对象。
数组元素的遍历
使用普通for循环来实现
- 思路:通过普通for循环,获得[0, 数组长度-1]的合法索引取值,然后再通过索引获得数组元素
- 优势:遍历的过程中,可以获得数组的合法索引值,因此遍历过程中我们可以操作数组中的元素。
- 劣势:语法复杂,效率较低。
- 使用场合:遍历数组的过程中,如果想要获得数组的合法索引取值,或者想要在遍历过程中操作数组元素,则“必须”通过普通for循环来实现。
使用增强for循环来实现
语法:
/* for(数据类型 变量名 : 数组或集合){ //循环体 } */ int[] arr = {1,23,4,5}; //增强for循环 for(int element : arr){ System.out.println(element); }优势:语法简洁,效率较高。
劣势:遍历的过程中,不能获得数组的合法索引值,因此遍历过程中我们无法操作数组中的元素。
使用场合:遍历数组的过程中,如果无需获得数组的合法索引取值,也就是遍历数组过程中无需操作数组元素,则建议通过增强for循环来实现。
快速使用增强for循环来遍历数组:数组名.for + enter
强调:通过length属性获得数组空间长度,则该操作的效率是非常低,因此在循环中切记不要使用length属性来获得数组空间长度。
**建议定义一个数组长度变量来循环
栈内存的概述
存储:局部变量
–> “基本数据类型”的局部变量,则在栈内存中存储的是”数据值”。
–> “引用数据类型”的局部变量,则在栈内存中存储的是”地址值”。
特点:
- 栈内存具备”先进后出”或”后进先出”的特点,类似于生活中的”子弹夹”。
- 栈内存是一块连续的存储空间,由虚拟机分配,效率高!
- 栈内存由虚拟机来管理,也就是无需程序员来手动管理内存。
- 虚拟机会为每个线程创建一个栈内存,用于存放该线程执行方法的信息。
存储:对象(数组)
特点:
- 堆内存不是一块连续的存储空间,分配灵活,但是效率低。
- 堆内存理论上需要程序员来手动管理,但是实际上交由”垃圾回收机制”来管理。
- 虚拟机中只有一个堆内存,被所有的线程共享。
数组反转
需求:将数组元素反转,原数组{5, 12, 54,7676,9},反转后为:{9, 676, 54, 12, 5}。
要求:使用两种方式来实现
- 方式一:创建一个新的数组,用于保存反转之后的结果。
- 缺点:
- 需要创建新的数组,浪费了存储空间。
- 需要完整遍历整个数组,浪费了执行时间。
- 缺点:
- 方式二:使用“首尾元素交换位置”的思路来实现。
- 优点:
- 无需创建新的数组,节约了存储空间。
- 只需遍历数组长度的一半,节约了执行时间。
- 优点:
数组工具类
- 问题:在前面的学习中,我们把操作数组的静态方法放到了不同的类中,因此想要调用这些静态方法的时候,我们首先得明确该方法在那个类中,然后才能通过“类名”来调用这些静态方法,因此调用这些方法的时候非常不方便。
- 解决:定义一个“数组工具类”,然后把操作数组的静态方法都放到该“数组工具类”中。
Arrays工具类的概述
- Arrays工具类在”java.util”包中,因此我们使用Arrays工具类的时候,必须通过import关键字导入Arrays类,然后才能使用Arrays工具类。
- Arrays工具类我们称之为“数组相关的工具类”,在Arrays类中提供了很多操作数组的“静态方法”,因此我们调用这些方法的时候,直接通过类名.来调用。
Arrays工具类的方法
public static String toString(int[] a){...} //作用:把数组转换为字符串并返回,也就是获得数组中的元素,然后把这些元素拼接成字符串并返回。 public static void fill(int[] arr, int val){...} //作用:数组的填充操作,把arr数组中的所有元素设置为val public static void sort(int[] arr){...} //作用:给数组元素执行“排序”操作,默认为“升序”排序 public static void sort(int[] arr, int fromIndex, int toIndex){...} //作用:对“指定范围”的数组元素执行“升序”排序 //范围:从fromIndex索引位置开始(包含),到toIndex索引位置结束(不包含)。 //注意:fromIndex取值范围在[0,数组长度-1]之间,toIndex取值范围在[0,数组长度]之间,并且必须满足toIndex大于fromIndex public static void binarySearch(int[] arr, int key){...} /* 作用:二分查找,查询key在arr数组中的索引位置。 返回值:如果查询元素在数组中存在,则返回该元素在数组中的索引位置;如果查询的元素在数组中不存在,则返回负数即可。 */ public static int binarySearch(int[] arr, int fromIndex, int toIndex, int key){...} /* 作用:对“指定范围”的数组元素执行二分查找操作,此处要求arr数组为升序排序。 范围;从fromIndex索引位置开始(包含),到toIndex索引位置结束(不包含)。 注意:fromIndex取值范围在[0, 数组长度-1],toIndex取值范围在[0,数组长度]之间,并且必须满足toIndex大于fromIndex。 返回值:如果查询元素在数组中存在,则返回该元素在数组中的索引位置;如果查询的元素在数组中不存在,则返回负数即可。 */ public static int[] copyOf(int[] original, int newLength){...} /* 作用:从索引为0的位置开始拷贝,一共拷贝newLength个数组元素并返回。 注意:此处newLength取值范围在[0,数组长度]之间。 */ Public static int[] copyOfRange(int[] original, int from, int to){...} /* 作用:拷贝指定索引范围的数组元素 范围:从from索引位置开始(包含),到to索引位置结束(不包含)。 注意:from取值范围在[0,数组长度 - 1]之间,to取值范围在[0,数组长度]之间,并且必须满足to大于from */ public static boolean equals(int[] arr1, int[] arr2){...} /* 作用:判断arr1和arr2两个数组是否相等。 返回值:如果arr1和arr2的地址值相等或arr1和arr2的数组元素一一对应,则都返回true,否则一律返回false。 */
方法的可变参数(掌握)
1、可变参数的引入
需求:定义一个方法,用于获得指定两个int类型数据之和。
public static int add(int num1, int num2){...}
可变参数的语法
语法:数据类型 … 可变参数名
eg:int … arr
可变参数的注意点
“可变参数”必须存在于“形参列表”中,并且“可变参数”必须在形参列表“最末尾”。
–> 也就是说,方法的形参列表中最多只能定义一个可变参数(0或1)
在方法体中,我们可以把可变参数当成“数组”来使用,本质上可变参数就是数组的另外一种语法表现形式。
–> eg:调用方法的是,实参为”int类型的数组”,则方法的形参可以为“int类型的可变参数”。
可变参数的使用场合
- 定义一个方法的时候,参数的类型都相同,但是参数的个数不确定时。
数组的核心特点
数组是一块连续的存储空间,则意味着相邻两个元素的存储空间是紧挨着的。
数组存储的是相同数据类型的元素,则意味着每个元素占用的字节数相同。
常见数组则必须明确数组的空间长度,数组一旦创建成功,则数组的空间长度就不能改变。
根据索引操作【改和查】
结论:根据索引操作元素效率非常高,甚至是所有数据结构中效率最高的。
依据:数组是一块连续的存储空间,则意味着相邻两个元素的存储空间是紧挨着。
–> 数组存储的是相同数据类型的元素,则意味着每个元素占用的字节数相同。
–> 寻址公式:首地址 + 索引值 * 每个元素占用的字节数
根据索引删除元素【删】
结论:根据索引删除元素的效率非常低,因为需要大量的挪动数组元素。
依据:数组是一块连续的存储空间,则意味着相邻两个元素的存储空间是紧挨着。
–> 常见数组则必须明确数组的空间长度,数组一旦创建成功,则数组的空间长度就不能改变了
根据索引插入元素【增】
结论:根据索引插入元素的效率非常低,因为需要大量挪动数组元素+扩容操作。
依据:数组时一块连续的存储空间,则意味着相邻两个元素的存储空间时紧挨着。
–> 常见数组则必须明确数组的空间长度,数组一旦创建成功,则数组的空间长度就不能改变啦。
手写冒泡排序
public static void bubbleSort(int[] arr){ //外部共需要排序length-1次 for (int i = 0; i < arr.length-1; i++) { boolean b = true; //内部比较第一次比较length-1次,随后逐次减一 for (int j = 0; j < arr.length-1-i; j++) { if (arr[j] > arr[j+1]){ int num = arr[j]; arr[j] = arr[j+1]; arr[j+1] = num; b = false; } } if (b){ return; } } }
二维数组(矩阵,较难)
二维数组的定义
- 数组中的每个元素都是一堆数组,这样的数组我们就称之为“二维数组”。
二维数组的声明
明确:所谓二维数组的声明,指的就是给二维数组取一个名字,类似于“变量的声明”。
语法1:
//数据类型[][] 数组名; int[][] arr1; String[][] arr2;语法2:
//数据类型[] 数组名[]; int[] arr1[] String[] arr2[]注意:实际开发中,我们建议使用”语法1”来声明二维数组,因为“数据类型 [ ] [ ] ”代表的是“二维数组类型”。
二维数组的创建
明确:所谓二维数组的创建,指的就是在堆内存中为二维数组开辟存储空间。
方式一:创建“等长”的二维数组(动态)
//语法:数据类型[][] 数组名 = new 数据类型[m][n]; // m: 设置二维数组得空间长度 //n:设置一维数组的空间长度 int[][] arr1 = new int[3][3]; String[][] arr2 = new String[3][4];方式二:创建“不等长”的二维数组(动态)
//语法:数据类型[][] 数组名 = new 数据类型[m][]; //m:设置二维数组的空间长度 int[][] arr1 = new int[3][]; String[][] arr2 = new String[4][];方式三:静态创建的二维数组(静态)(等长|不等长)
//数据类型[][] 数组名 = {{数据1,数据2}, {数据3,数据4},...} int[][] arr1 = {{11,22,33},{55,66,77},{13,56,78}}; String[][] arr2 = {{"aa","bb"},{"cc","dd","yt"}}; //数据类型[][] 数组名 = new 数据类型[][]{{数据1,数据2}, {数据3,数据4},...}; int[][] arr1 = new int[][]{{11,22,33},{55,66,77},{13,56,78}}; String[][] arr2 = new String[][]{{"aa","bb"},{"cc","dd","yt"}};注意:通过大括号创建出来的二维数组,我们无法直接作为方法的”实参”和”返回值”,因为编译器不认识大括号创建的二维数组。
异常及断点调试
调试
debug调试的作用
- 查看代码的执行顺序,分析变量值的变化,从而找到问题的并解决问题。
debug的调试步骤
第一步:在代码可能出现问题的位置,我们在该位置打一个断点。
–> 在该代码行号左侧位置,我们单击打一个断点(红色圆圈)
第二步:开启debug调试来执行程序,则代码就会停留在打断点的位置。
–>方式一: 点击类名或main方法左侧绿色按钮,然后选中”Debug Xxx.main()”即可。
–> 方式二:在代码编辑区域,我们鼠标右键然后选中”Debug Xxx.main()”即可。
–> 方式三:已经执行程序后,我们点击工具栏或控制台左侧的”debug按钮”。
明确:开启debug调试之后,则就会出现debug窗口,debug窗口的作用如下:
Debugger
- Frames:显示代码停留的位置(包、类、方法和行号)
- Variables:显示当前方法已经执行过的变量的值
Console
- 显示输出的内容或获取输入的内容。
第三步:控制代码的执行,也就是通过Debug窗口来控制代码的执行。
- F8:执行下一行代码。
- F7:进入执行方法体中的代码。
- shift + F8:结束当前方法,回到方法的调用位置。
- Alt + F9:直接执行到下一个断点的位置。
- Alt + F8:计算并执行某行未执行代码的运算结果。
第四步:结束debug调试。
首先,取消断点(单击取消);然后,结束程序(点击红色按钮);最后,关闭debug窗口。
异常的概述
- 什么是异常?
- 程序在执行过程中,发生的各种不正常情况,我们就称之为“异常”。
- 例如:算数异常、数组索引越界异常、空指针异常和类型转换异常等等
- 什么是异常类?
- 用于封装和描述各种不正常情况的类,我们就称之为“异常类”。
- 例如:ArithmeticException、ArrayIndexOutOfBoundsException、NullPointerException和ClassCastException等等。
- 学习异常的好处?
- a)学习异常之后,就能够实现把“正常逻辑代码”和“错误逻辑代码”相分离。
- b)没有学习异常,则某些情况下无论我们如何处理,则都可能无法满足需求。
- 异常的处理机制?
- 在java语言中,使用面向对象的思想来处理异常。在可能出现问题的位置,我们创建并抛出一个异常对象,该异常对象中封装了异常的详细描述信息(异常类名、异常位置和异常原因),从而实现“正常逻辑代码”和“错误逻辑代码”相分离。
常见异常
- 算数异常(ArithmeticException)
- 原因:做除法操作的时候,如果分母为零,则就会抛出算数异常。
- 数组索引越界异常(ArrayIndexOutOfBoundsException)
- 原因:根据索引操作数组元素的时候,如果操作的索引值越界,则就会抛出数组索引越界异常。
- 空指针异常(NullPointerException)
- 原因:我们对空对象做操作,则就会抛出空指针异常。
异常的体系
异常体系的引入
- 在程序执行的过程中,可能会发生各种各样的不正常情况,因此我们就需要很多的异常类来封装和描述这些不正常情况,我们对这些异常类进行“向上提取”,那么就得到了异常的继承体系。
异常体系的概述
所有Java类的老祖宗为Object类,所有不正常情况类的老祖宗就是Throwable类,那么Throwable类的继承体系如下:
/* Throwable --> 所有不正常情况类的老祖宗 |-- Error --> 所有错误类的老祖宗 |-- Exception --> 所有异常类的老祖宗 */ //注意:a)如何查看某个类的继承体系呢???选中该类,然后使用“ctrl + h”来查看继承体系。 // b)所有错误类的后缀都以“Error”来结尾,所有异常类的后缀都以“Exception”来结尾。
Throwable的概述
- Throwable类是所有不正常情况类的老祖宗,Error类和Exception类都属于Throwable的子类,因此Error类和Exception类都能使用Throwable提供的方法。
Error类的概述
- Error类是所有“错误类”的老祖宗,并且Error类继承于Throwable类,因此Error类能使用Throwable类提供的所有方法。
- Error描述的是“资源耗尽”或“虚拟机内部错误”等不正常情况,因此开发中遇到这样的不正常情况,我们程序员是无法解决的(不结束程序的前提来解决),也就是程序员只能先结束程序,然后再去重新修改代码来搞定这种不正常情况。
Exception类的概述
- Exception类是所有“异常类”的老祖宗,并且Exception类继承于Throwable类,因此Exception类能使用Throwable类提供的所有方法。
- Exception类描述的是“程序员能够解决”的不正常情况,开发中我们遇到了Exception异常,则需要拼尽全力去解决该异常(不结束程序的前提来解决)。
- Error属于程序员无法解决的不正常情况,而Exception属于程序员能够解决的不正常情况。
Error与Exception的区别
- 我开着车走在路上,一头猪冲在路中间,我刹车,这叫一个异常。
- 我开着车在路上,发动机坏了,我停车,这叫错误。
- 发动机什么时候坏?我们普通司机能管吗?不能。发动机什么时候坏是汽车厂发动机制造商的事。
自定义异常类(掌握)
自定义异常类的引入
- 问题:给学生年龄复制的时候,则赋值的年龄不能为负数。
- 解决:如果赋值的年龄为负数,则无论我们给年龄赋值任何数据都不合理,那么最好的方案就是如果年龄不合法就抛出异常。
- 问题:如果赋值的年龄不合法,则应该抛出“学生年龄不合法异常”,该如何实现???
- 解决:使用“自定义异常类”来解决。
什么时候使用自定义异常类
- 当Java语言提供的异常类无法满足我们的需求,则我们就可以使用“自定义异常类”来满足需求。
自定义异常类的要求
要求1:自定义异常类必须继承于异常体系中的类,一般继承于Exception类或RuntimeException类。
–> 只有继承于异常体系的中的类,该类才具备可抛型,也就是才能使用throw和throws关键字。
要求2:自定义异常类必须提供两个构造方法,其中一个为无参构造方法,另外一个为字符串参数的有参构造方法。
–> 使用字符串参数的有参构造方法,我们可以用于封装和保存异常出现的原因,从而传递给父类的异常来保存。
异常产生的过程
- 如果在方法体中抛出了异常,而我们在方法体中又没有处理该异常,则就会把该异常继续抛给方法的上层调用者,也就是抛给方法的上层调用者来处理。
- 如果方法的上层调用者依旧没有处理该异常,那么就会继续把该异常抛给方法的上层调用者来处理,以此类推,如果方法的上层调用者都没有处理该异常,那么最终就把该异常抛给了main方法的调用者(虚拟机),而虚拟机也不会处理该异常,那么程序就终止啦。
手动抛出异常(throw)
- 在可能出现异常的位置,我们创建并抛出一个异常对象,该异常对象中包含了异常的详细描述信息(异常类名、异常位置和异常原因),从而实现了“正常逻辑代码”和“错误逻辑代码”相分离。
- 注意:throw关键字只能在方法体中使用,也就是我们只能在方法体中来手动抛出一个异常。
异常的分类(重点)
异常的分类的引入?
问题:“学生年龄越界异常类”继承于Exception类和RuntimeException类的区别?
答案:“学生年龄越界异常类”继承于Exception类,则抛出“学生年龄越界异常”就会出现编译错误。
“学生年龄越界异常类”继承于RuntimeException类,则抛出 “学生年龄越界异常”就不会出现编译错误。
异常的分类的概述
运行时异常
–> 包含:RuntimeException类及其所有子类。
–> 特点:程序编译时,不强制我们对抛出的异常进行处理(可以处理,也可以不处理)
编译时异常
–>包含:Exception类及其所有子类(排除运行时异常)。
–>特点:程序编译时,强制我们对抛出的异常进行处理(必须处理,否则就会编译错误)。
异常的处理的方式
声明异常(throws)
–> 属于“消极”的处理方式,本质上并没有处理该异常。
捕捉异常(try…catch…finally)
–>属于“积极”的处理方式,本质上已经解决了该异常。
不正常情况的分类补充
可检查异常(CheckedException)
–>包含:编译时异常
–>特点:程序在编译时期,能够检查出程序中出现的不正常情况。
不可检查异常(UnCheckedException)
–>包含:Error和运行时异常
–>特点:程序在编译时期,不能够检查出程序中出现的不正常情况。
声明异常(throws)
声明异常的概述
- 声明异常属于“消极”的处理方式,本质上并没有解决该异常。
- 程序中出现了异常,此时我们又无法处理该异常,那么就使用声明异常来处理。
声明异常的使用?
- 当方法中“可能”会出现异常,此时我们又无法处理该异常,那么就可以使用“声明异常”来处理。也就是在方法声明的末尾,使用throws关键字将方法体中可能抛出的异常声明出来,然后报告给方法的调用者,交给方法的调用者来处理。
声明异常的语法
[修饰符] 返回值类型 方法名(形参列表) throws 异常类1, 异常类2, 异常类3, ... { // 方法体 return [返回值]; }
捕捉异常类(try…catch…finally)
捕捉异常的概述
- 捕捉异常属于“积极”的处理方式,本质上就已经处理了该异常。
- 当程序中可能出现异常,此时我们恰好能解决该异常,则就使用捕捉异常来处理。
try…catch组合
语法
try{ //书写可能出现异常的代码 }catch(异常类 对象){ //用于处理捕获到的异常。 }执行:如果try代码块中没有出现异常,则try代码块中的代码正常执行完毕,然后就直接执行try…catch之后的代码。 如果try代码块中出现了异常,则catch代码块就会立刻捕获到该异常,然后就执行catch代码中的代码,最后再执行try…catch之后的代码。
try…多catch组合
语法:
try{ //书写可能出现异常的代码 }catch(异常类 对象){ //用于处理捕获到的异常 }catch(异常类 对象){ //用于处理捕获到的异常 } ...作用:使用try…多catch组合,我们可以实现对try代码块中出现的异常进行“针对性”的处理。
注意:
使用捕捉异常的时候,建议使用“Ctrl + Alt + T”快捷键来生成try…catch…finally代码。
- 选择中可能出现异常的代码,然后使用使用“Ctrl + Alt + T”快捷键来捕捉异常的代码。
在JDK1.8之后,则我们还以可以这样来处理:
catch (NullPointerException | ArrayIndexOutOfBoundsExceptionexception) { ... }- 以上操作不建议使用,因为使用以上操作无法实现对try代码块中出现的异常进行针对性的处理。
使用try…多catch组合的时候,建议把子类异常catch放在前面,把父类异常catch放在后面,否则就会编译错误。
- 捕获异常的时候,属于“从上往下”来顺序匹配,如果父类异常catch放前面,则后面的子类异常catch将永远无法执行。
try…多catch…finally组合
语法:
try{ //书写可能出现异常的代码 }catch(异常类 对象){ // 用于处理捕获到的异常 } catch(异常类 对象){ // 用于处理捕获到的异常 } … finally{ // 无论是否出现异常,则都会执行finally中代码 }
方法重写之异常(掌握)
原则:子类重写方法声明的异常类型必须小于等于父类被重写方法声明的异常类型【辈分】。
–>此处说的异常,指的是编译时异常,而运行时异常不用管!
要求:a)如果父类被重写方法没有声明异常,则子类重写方法也不能声明异常。
b)如果父类被重写方法声明了异常,则子类重写方法声明的异常类型必须小于等于父类被重写方法声明的异常类型(辈分)。
异常链(了解)
解释:在catch代码块中,我们抛出一个描述更加详细的异常,这就是异常链。
// 分母为零异常类 class DenominatorZeroException extends Exception { public DenominatorZeroException() { } public DenominatorZeroException(String message) { super(message); } } public class Test03 { /** * 功能:获得两个数相除的结果 * 问题:a)除法运算,如果分母为0,则不应该返回任何结果,而此处却返回了结果为0。 * b)除法运算,如果分母为0,则抛出算数异常,那么意味着异常描述不够清晰。 * 解决:使用“异常链”来解决。 */ public static int division(int fenZi, int fenMu) throws DenominatorZeroException { // 1.定义一个变量,用于保存运算的结果 int result = 0; // 2.执行除法运算,并处理了可能出现的算数异常 try { result = fenZi / fenMu; } catch (ArithmeticException exception) { // 需求:在此处,我们需要抛出一个描述更加详细的异常 throw new DenominatorZeroException("分母为零异常,fenMu:" + fenMu); } // 3.返回除法运算的结果 return result; } public static void main(String[] args) { try { int result = division(5, 0); System.out.println(result); } catch (DenominatorZeroException e) { e.printStackTrace(); } System.out.println("over"); } }
类和对象
面向过程
封装(堆功能method的封装)
典型:c语言
特点:以线性的思维来思考解决问题,强调一步一步的实现。
–> 强调程序员是一个“实施者”,类似于公司中的“小职员”。
优点:效率高。
缺点:程序的复用性、可维护性和可扩展性较低。
使用场合:适用于“小型”的程序,例如:计算器、嵌入式开发等等
面向对象
封装(对数据field和功能method做的封装)、继承和多态。
典型:C++、C#、java等。
特点:以非线性的思维来思考解决问题,强调宏观上的把控。
–> 强调程序员是一个“指挥官”,类似于公司中的“小老板”。
优点:程序的复用性、可维护性和可扩展性较高。
缺点:效率低。
使用场合:适用于“大型”的程序,例如:京东、淘宝、微信等等。
面向对象编程的特点
- 宏观上采用面向对象的思维来把控,微观实施上依旧采用的是面向过程,即:面向对象中包含了面向过程。
类和对象(理解)
对象(instance)
- 从编程的角度来理解:万物皆对象。
- eg:教室里面的每个学生、每个凳子、每张椅子。。。
- 每个对象都是“独一无二”的,类似于每个同学都是“独一无二”的。
类(class)
- 从编程的角度来理解:类就是对一类事物的抽象,抽象就是提取这一类事物的共同属性和行为,这样就形成了类。
- eg:班上的每个同学都有姓名、年龄和成绩等属性,每个同学都有吃饭、睡觉和学习等行为,则我们对班上的同学进行向上提取,那么就得到了学生类。
类和对象
从编程的角度来分析:我们以类为模板,然后实例化出对象。
–> 先有类,后有对象。
–> 类是对象的模板,对象是类的实例。
eg:我们以小汽车图纸(类)为模板,然后生产出一辆一辆的小汽车(对象)。
如何定义类
语法:[修饰类] class类名{ //书写的代码 }
注意:
- 使用class关键字修饰的就是类,也就是类必须使用class来修饰。
- 类名必须满足“标识符”的命名规则,必须满足“大驼峰”的命名规范,并且最好“见名知意”。
- 使用“public”关键字修饰的类,则类名必须和源文件名字保持一致,否则就会出现编译错误。
类中的组成
- 数据(属性),我们使用“变量”来存储类中封装的数据,类中的变量有:
- 成员变量:又称之为“实例变量”或“非静态变量”,因为是从属于“对象”的。
- 静态变量:又称之为“类变量”,从属于“类”的。
- 功能(行为),我们使用“方法”来封装类中的功能。
- 成员方法,又称之为“实例方法”或“非静态方法”,从属于“对象”的。
- 静态方法,又称之为“类方法”,从属于“类”的。
成员变量的概述
定义位置:在类中,代码块和方法体之外。
定义语法:[修饰符] 数据类型 变量名;
–>定义成员变量的时候,则不允许使用static关键字来修饰。
操作成员变量的语法:对象.成员变量名
–> 通过 “对象.成员变量名” 就能找到该成员变量的存储空间,然后就能对该成员变量取值和赋值的操作。
–> 在成员方法中,想要操作当前类的成员变量,则我们可以直接通过“成员变量名”来操作。
–> 定义成员方法的时候,则不允许使用static关键字来修饰。
调用成员方法的语法:对象.成员变量名(实参列表);
–> 注意:在成员方法中,想要调用当前类的成员方法,则我们可以直接通过“成员变量名(实参列表);”来实现。
实例化对象的概述
语法
类型 对象 = new 类名(实参列表); Student stu = new Student(); Scanner input = new Scanner(System.in);
成员变量的默认值
- 明确:“成员变量”和“数组元素”都有默认值,并且默认值规则一样。
- 整数型(byte、short、int和long)成员变量的默认值为:0;
- 浮点型(float和double)成员变量的默认值为:0.0;
- 布尔型(boolean)成员变量的默认值为:false;
- 字符型(char)成员变量的默认值为:’\u0000’ –> 代表的是空格字符
- 引用数据类型(数组、字符串、类和接口等等)成员变量的默认值为:null
成员变量的初始化
- 最先执行“默认初始化”,然后执行“显示初始化”,最后执行“指定初始化”。
创建对象时的内存分析
- 结论:以类为模板来创建对象,则只需要为类中的成员变量在堆内存中开辟存储空间,而成员方法是调用的时候自动在栈内存中开辟栈帧。
- 注意:每个对象都是“独一无二”的,因为每次创建对象都会在堆内存中开辟存储空间。
成员变量和局部变量的对比
- 定义位置区别
- 成员变量:在类中,代码块和方法体之外。
- 局部变量:在类中,代码块或方法体之内。
- 存储位置区别
- 成员变量:存储在“堆内存”中。
- 局部变量:存储在“栈内存”中。
- 生命周期区别
- 成员变量:随着对象的创建而“出生”,随着对象的销毁而“死亡”。
- 局部变量:定义变量的时候“出生”,所在作用域执行完毕就“死亡”。
- 默认值的区别
- 成员变量:成员变量有默认值,并且默认值规则和数组元素默认值规则一模一样。
- 局部变量:局部变量没有默认值,因为只声明未赋值的局部变量,则不能做取值操作。
- 修饰符的区别
- 成员变量:可以被public、protected、private、static、final等修饰符修饰。
- 局部变量不能被public、protected、private、static修饰,只能被final修饰。
成员变量和局部变量的使用
- 明确:当成员变量和局部变量同名的时候,则默认采用的是“就近原则”,也就是“谁离的近,就执行谁”。
- 问题:当成员变量和局部变量同名的时候,我们该如何区分?
- 解决:局部变量采用“就近原则”来区分,成员变量使用“this”关键字来区分。
通过new关键字来创建对象,则创建出来的对象分为两种
- 匿名对象,指的就是“没有名字的对象”,例如:new Tiger();
- 非匿名对象,指的就是“有名字的对象”,例如:Tiger tiger = new Tiger();
- 开发中,匿名对象很少使用,但是以下两种场合建议使用匿名对象来实现。
- 创建出来的对象,仅仅只调用一次成员方法,则该对象就建议使用匿名对象来实现。
构造方法(构造器或构造函数)
语法
[修饰符] 类名(形参列表){ //方法体 }注意:【构造方法的特点】
构造方法中没有“返回值类型”,因为在构造方法中不允许有“返回值”。
–> 构造方法中没有“返回值”,则构造方法中只有“return;”,那么我们就省略”return;”。
构造方法的名字必须为“类名”,也就是构造方法名采用”大驼峰”来命名。
–> 构造方法名采用“大驼峰”,而成员方法名和静态方法名采用“小驼峰”。
构造方法就是一个“特殊”的方法,并且构造方法应该通过new关键字来调用。
构造方法专门给成员变量做初始化,也就是构造方法不为静态变量做初始化。
构造方法可以没有(默认一个无参构造方法),也可以有多个构造方法,他们之间构成重载关系。
如果定义有参构造方法,则无参构造方法被自动屏蔽。
构造方法不能被继承。
构造方法不能手动调用,在创建类实例的时候自动调用构造方法。
创建对象的步骤
分析“new Student();”的执行顺序,也就是分析创建对象的执行步骤:
- 创建对象,并给成员变量开辟存储空间;
- 给成员变量做“默认初始化”;
- 给成员变量做“显式初始化”;
- 调用构造方法,给成员变量做“指定初始化”。
创建对象的时候,是谁来完成的呢?
- new关键字负责创建对象,构造方法负责给成员变量做指定初始化操作,创建对象的时候new关键字和构造方法缺一不可。
构造方法的作用
- 创建对象的时候new关键字和构造方法缺一不可(了解)。
- 通过构造方法来给成员变量做指定初始化操作,从而实现代码的复用【核心】。
无参构造方法的概述
- 作用:用于给成员变量做初始化操作,例如在无参构造方法中给int类型数组做开辟存储空间的操作。
- 注意:如果某个类中没有显式地提供构造方法,则程序编译时会默认为这个类提供一个无参构造方法。
有参构造方法的概述
- 作用:用于给成员变量做初始化操作,例如在有参构造方法中我们将形参的值赋值给成员变量来保存。
- 注意:
- 建议形参的名字和成员变量名保持一致,然后在构造方法中通过this来操作成员变量。
- 如果一个类显式地提供了构造方法,则程序编译时就不会为该类提供默认的无参构造方法了。
- 建议每个类都应该提供无参构造方法,避免在继承体系中子类找不到父类的无参构造方法。
构造方法的重载
- 构造方法依旧可以实现方法的重载,调用构造方法的时候会根据实参的“个数”和“类型”来选中调用合适的构造方法。
this关键字(重点)
this关键字的概述
- 创建一个对象成功之后,则虚拟机就会动态地创建一个引用,该引用指向的就是新创建出来的对象,并且该引用的名字就是this。
this关键字指的是什么?
在构造方法中,this指的是什么?
在构造方法中,this指的是“新创建出来的对象”。
在成员方法中,this指的是什么?
在成员方法中,this指的是“方法的调用者对象”。
this关键字的作用
操作成员变量,语法:对象.成员变量名
- 如果成员变量和局部变量的名字相同,则我们必须通过this关键字来操作成员变量,使用就近原则来操作局部变量。
- 如果成员变量和局部变量的名字不同,则我们可以通过this关键字来操作成员变量,也可以忽略this关键字来操作成员变量。
- –> 忽略this关键字来操作成员变量,则编译时会默认添加this关键字来操作。
调用成员方法,语法:对象.成员变量名(实参列表);
调用当前类的别的成员方法时,我们可以通过this关键字来调用,也可以忽略this关键字来调用。
–> 忽略this关键字来调用成员方法,则编译时会默认添加this关键字来操作。
调用构造方法,语法:this(实参列表);
作用:调用“当前类”的别的构造方法,此处仅仅调用方法并不创建对象,从而实现了代码的复用。
注意:
“this(实参列表)”只能存在于构造方法中,并且必须在构造方法有效代码的第一行。
–> “this(实参列表)”必须在构造方法有效代码的第一行,则意味着一个构造方法中最多只能有一个“this(实参列表)”。(0或1)
构造方法切记不能“递归”调用,否则就会陷入死循环,从而造成程序编译错误!
–> 在构造方法中,我们不允许通过“this(实参列表)”来自己调用自己,否则就会编译错误!
在一个类中,不可能所有的构造方法中都存在“this(实参列表)”,因为这样肯定会陷入死循环。
–> 一个类中,可以定义多个构造方法,但是至少有一个构造方法中没有“this(实参列表)”。
静态变量(重点)
静态变量的引入
- 需求:班上所有同学的姓名、年龄和成绩等属性,并且所有的学生都共享同一个教室和饮水机。
- 解决:定义一个Student类,然后在Student类中定义姓名、年龄、成绩、教室和饮水机等成员变量即可。
静态变量的概述
- 在类中,代码块和方法体之外,使用static关键字修饰的变量,我们就称之为“静态变量”。
静态变量的特点
静态变量优先于对象存在,随着类的加载就已经存在了。
一个类中,每个静态变量都只有一份,为类和对象所共享。
我们可以通过“类名”来操作静态变量,也可以通过“对象”来操作静态变量。
语法1:类名.静态变量 –> 建议
语法2:对象.静态变量 –> 不建议
类的加载过程分析
第一次使用某个类的时候,就会加载该类的信息进入方法区,如果该类中存在静态变量,则还会在方法区中为该静态变量开辟存储空间并设置默认值。
问题1:什么时候执行加载类的操作呢?
–> 第一次使用某个类的时候,则就会执行加载类的操作。
问题2:一个类会加载几次呢?
–> 每个类都只会加载一次,因为第一次使用某个类的时候就执行加载类的操作。
问题3:什么是方法区?方法区存储的内容是什么??
–> 方法区就是一块存储空间,并且方法区属于堆内存中的一部分,方法区用于存储类的信息、静态变量等等内容。
问题4:静态变量什么时候开辟存储空间呢?
–> 加载类的时候,则就会把该类中的静态变量在方法区中开辟存储空间,也就意味着静态变量优先于对象存在。
问题5:一个类中的静态变量,会开辟几次存储空间?
–> 因为类只会加载一次,因此每个类中的静态变量就只有一份,也就是每个静态变量只会开辟一次存储空间。
问题6:静态变量的默认值是什么?
–> 静态变量和成员变量都有默认值,并且他们的默认值规则一模一样。
成员变量和静态变量的对比
- 存储位置区别
- 成员变量:存储在堆内存中。
- 静态变量:存储在方法区中。
- 生命周期
- 成员变量:随着对象的创建而“出生”,随着对象的销毁而”死亡”。
- 静态变量:随着类的加载而“出生”,随着程序执行完毕而“死亡”。
- 创建次数的区别:
- 成员变量:对象创建多少次,则成员变量就创建多少次。
- 静态变量:因为类只会加载一次,因次静态变量就只会创建一次。
- 调用语法区别
- 成员变量:必须通过”对象”来调用。
- 静态变量:可以通过“类名”来调用,也可以通过“对象”来调用。
成员变量和静态变量的使用
- 成员变量:如果存储的是“特有数据”,则就使用成员变量来存储。
- 静态变量:如果存储的是“共享数据”,则就是用静态变量来存储。
代码块
代码块的分类
- 局部代码块
- 静态代码块
- 构造代码块(非静态代码块)
局部代码块的概述
- 定义位置:在类中,代码块或方法体的内部。
- 定义个数:任意多个。
- 执行顺序:从上往下,顺序执行。
- 注意事项:
- 在局部代码块中定义的变量,则该变量就只能在当前作用域中使用,不能在代码块之外使用。
静态代码块的概述
定义位置:在类中,代码块和方法体之外(必须使用static来修饰)。
定义个数:任意多个
执行顺序:从上往下,顺序执行
注意事项:a)加载某个类的时候,就会执行该类中的静态代码块,并且静态代码块只会执行一次。
–>执行时间:加载类的时候,就会执行该类中的静态代码块。
–> 执行次数:因为类只会加载一次,因此静态代码块就只会执行一次。
b)在静态代码块中,我们可以直接操作当前类的静态内容,但是不能直接操作当前类的成员内容和this。
–> 原因:加载类的时候,就会执行该类中的静态代码块,则执行静态代码块的时候对象都还未创建。
c)加载类的时候,静态变量和静态代码块属于“从上往下,顺序执行”,建议把静态变量定义在静态代码块之前。
–> 注意:在静态代码块中,我们“未必”能直接操作当前的静态变量。
d)在静态代码块中定义的变量,则该变量就只能在当前作用域中使用,不能再代码块之外使用。
使用场合:开发中,我们经常再静态代码块中完成对静态变量的初始化操作(常见)。
–>例如:创建工厂、加载数据库初始信息等等。
构造代码块的概述
- 定义位置:在类中,代码块和方法体之外(不能使用static来修饰)
- 定义个数:任意多个
- 执行顺序:从上往下,顺序执行。
- 注意事项:
- 创建对象的时候,则就会执行该类中的构造代码块,对象创建了多少次则构造代码块就执行多少次。
- 执行时间:创建对象的时候,则就会执行该类中的构造代码块。
- 执行次数:对象创建了多少次,则该类中的构造代码块就执行多少次。
- 在构造代码块中,我们不但能直接操作当前类的静态内容,并且还能直接操作当前类的成员内容和this。
- 原因:执行代码块的时候,此时对象都已经创建完毕,因此就能操作当前类的成员内容和this。
- 创建对象的时候,成员变量和构造代码块属于“从上往下,顺序执行”,建议把成员变量定义在构造代码块之前。
- 注意:在构造代码块中,我们“未必”能直接操作当前类的成员变量。
- 在构造代码块中定义的变量,则该变量就只能在当前作用域中使用,不能在代码块之外使用。
- 使用场合:开发中,我们偶尔会在构造代码块中完成对成员变量的初始化操作。(不常见)
- 可以将各个构造方法中公共的代码提取到构造代码块。
- 匿名内部类不能提供构造方法,此时初始化操作可以放到构造代码块中。
- 创建对象的时候,则就会执行该类中的构造代码块,对象创建了多少次则构造代码块就执行多少次。
静态代码块、构造代码块和构造方法执行顺序?
–> 静态代码块 > 构造代码块 > 构造方法
包(package)
包的作用
- 我们使用包来管理类,也就是类应该放在包中。
- 包的出现,为类提供了多层的命名空间,也即是类的完整名字为”包名.类名”。
- 注意:不同的包中,我们可以定义同名的类;同一个包中,我们不允许定义同名的类。
如何定义包
包名必须满足“标识符”的命名规则,必须满足“单词全部小写,多个单词之间以’.’链接,并且做到顶级域名倒着写”的命名规范。
问题:以下两个包是否存在父子关系?【没有】
–> com.bjpowernode.demo com.bjpowernode.demo.test
如何使用包
–> 在源文件有效代码第一行,使用package关键字来声明当前源文件中的类在那个包中。
注意:通过IDEA新建的源文件,则源文件有效代码的第一行默认就有包声明;如果通过DOS命令来运行IDEA创建的源文件,则必须删除源文件中的包声明。
java语言提供的包
- java.lang 包含一些java语言的核心类,如String、Math、System等;
- java.awt 包含了构成抽象窗口工具集(abstract window toolkits)的多个类,这些类被用来构建和管理应用程序的图形用户界面(GUI);
- java.net 包含执行与网络相关的操作的类;
- java.io 包含能提供多种输入、输出功能的类;
- java.util 包含一些实用工具类,如定义系统特性、使用与日期日历相关的函数。
类的访问方式
简化访问
解释:当我们需要访问“java.lang”或“当前包”中的类时,则就可以直接使用“类名”来实现简化访问。
例如:访问“当前包”中的类
–> Tiger tiger = new Tiger(“老虎”, 18);
例如:访问“java.lang”中的类
–> String str = “hello world”;
带包名访问
解释:当我们需要访问“当前包”之外的类时(排除java.lang包中的类),则我们就必须通过“包名.类名”的方式来访问。
例如:访问”p1包”中的类
–> com.bjpowernode.p1.staticblock.student stu = new com.bjpowernode.p1.staticblock.student();
例如:访问“java.util”中的类
–> java.util.Scanner input = new java.util.Scanner(System.in);
import关键字的概述
解释:当我们需要访问“当前包”之外的类(排除java.lang包中的类),则必须通过“带包名”的方式来访问,则此访问方式太麻烦,想要实现简化访问,则就可以先通过import关键字导入需要访问的类,然后再通过“类名”来实现简化访问。
例如:访问“p1包”中的类
–> import com.bjpowernode.p1.staticblock.student;
–> Student stu = new Steudent();
例如:访问”java.util”中的类
–> import java.util.Scanner;
–> Scanner input = new Scanner(System.in);
import关键字的注意点
如果需要使用某个包中的多个类时,则我们可以通过”*”通配符来导入这个包中的所有类。
–> 注意:开发中,不建议使用“*”来导入某个包中的所有类,因此此方式效率非常低。
如果需要使用不同包中的同名类时,则其中一个类必须通过“带包名”的方式来访问。
–> 原因:通过import关键字导入多个不同包的同名类,则在源文件中使用导入的类时,无法区分。
在JDK1.5之后,还新增了静态导入,也就是能导入某个类中的静态属性和静态方法。
–> 例如:导入Math类中的静态属性
- 第一步:import static java.lang.Math.PI;
- 第二步:System.out.println(PI);
–> 例如:导入Math类中的静态属性和静态方法
- 第一步:import static java.lang.Math.*;
- 第二部:System.out.println(PI);
封装
问题:具备那三大特性的编程语言,我们才称之为面向对象语言?
–> 封装、继承、多态
封装的引入
问题1:给学生年龄赋值的时候,赋值的年龄不能为负数!
–> 使用“setter和getter”方法来解决
问题2:相同的代码在不同的包中,可能会发生编译错误!
–> 使用“权限修饰符”来解决
编程中的封装
- 核心:对于使用者而言,只需掌握其公开的访问方式,无需了解内部的具体实现细节。
封装的层次
- 面向过程:对功能做的封装,也就是使用方法来完成的封装。
- 面向对象:对数据和功能做的封装,也就是使用类来完成的封装。
封装的好处
- 封装的出现,提高了代码的安全性【了解】。
- 封装的出现,提高了代码的复用性【核心】。
权限修饰符
private,私有的,权限:只能在“当前类”中访问,因此我们称之为“类可见性”。
default,默认的,权限:只能在“当前类 + 当前包”中访问,因此我们称之为“包可见性”。
–> 注意:在权限修饰符中,没有default关键字,省略权限修饰符默认就是包可见性。
protected,受保护的,权限:只能在“当前类 + 当前包 + 别的包中的子类包”中访问,因此我们称之为“子类可见性”。
public,公开的,权限:只能在“当前类 + 当前包 + 加别的包”中访问,因此我们称之为“项目可见性”。
- 权限大小【由低到高】:private << default << protected << public
权限修饰符的使用
明确:实际开发中,“默认的”和“受保护的”很少使用,但是“私有的”和“公开的”却很常用。
private:default、protected和public都能修饰”成员变量”和“静态变量”。
–> 成员变量:因为存储都是“特殊数据”,因此使用private修饰。
–> 静态变量:因为存储是“共享数据”,因此使用public来修饰。
private:default、protected和public都能修饰”成员方法”和“静态方法”。
–> 如果该方法需要外界访问,则就把该方法使用public来修饰。
–> 如果该方法无需外界访问,也就是只为当前类服务,那么久把该方法使用private来修饰。
private:default、protected和public都能修饰“构造方法”。
–> 如果该类需要被外界实例化,则该类的构造方法就采用public来修饰;
–> 如果该类无需被外界实例化,则该类的构造方法就采用private来修饰。
注意:工具类中只有静态内容,因此工具类就无需被实例化,那么工具类的构造方法都采用了private修饰,eg:Arrays和Math等等。
定义类的时候,类只允许使用public和default,不允许使用private和protected来修饰。
–>使用public修饰的类(公开权限),则该类就能在整个项目中使用。
–> 使用default修饰的类(默认权限),则该类就只能在当前包中使用。
使用权限修饰符,则不允许修饰局部变量、局部代码块、静态代码块和构造代码块。
setter和getter
- setter和getter方法的概述
- 成员变量一律私有化(private),避免外界直接去访问成员变量,然后提供公开的setter和getter方法来操作私有的成员变量。
- setter方法的概述
- 作用:用于给私有的成员变量做赋值操作,并且还能对赋值的数据做检查和处理。
- getter方法的概述
- 作用:用于获取私有成员变量的值(取值操作),并且还能对获得的数据做统一的处理。
- setter和getter的注意点
- 通过构造方法给成员变量赋值,如果赋值的数据需要做检查和处理,则在构造方法中就必须调用setter方法来实现赋值操作。
- 给boolean类型成员变量提供getter方法的时候,此时getter方法的名字前缀必须是“is”开头,而不是能以“get”来开头。
- 给类提供“构造方法”和“setter和getter方法”的时候,则建议使用“alt + insert”快捷键来实现,而不建议手动写代码来实现。
继承
继承的引入
- 问题:讲师类和学生类中都有相同的name和age两个成员变量,都有相同的eat()和sleep()两个成员方法,因此需要实现代码的复用。
- 解决:使用“继承”来实现。
继承的本质
- 就是提取一系列类中相同的成员变量和成员方法,这样就得到了一个父类,从而形成了继承关系。
- 即:向上提取。
继承语法
[修饰符] class 父类{} [修饰符] class 子类 extends 父类{}继承的特点
- 子类不但能继承父类的成员变量和成员方法,并且子类还可以有自己特有的成员变量和成员方法。
- 即:子类对父类做的扩展。
继承的好处
- 继承的出现,提高了代码的复用性,从而提高了开发的效率。
- 继承的出现,让类与类之间产生了联系,为后面学习“多态”打下了技术铺垫。
- 强调:继承是一把“双刃剑”,父类代码一旦发生了变化,则就会影响所有的子类,使用继承的时候慎重。【高耦合】
哪些内容子类不能继承
- 父类私有的内容,子类不能继承。
- 父类的构造方法,子类不能继承。
- 父类静态的内容,虽然子类能够使用,但父类静态内容“不参与”继承。
- 强调:继承强调的是“对象”之间的关系,因此成员内容能参与继承,但是静态内容不参与继承。
继承的注意点
java语言采用的是“单继承”,C++语言采用的是“多继承”。
- 单继承:一个子类只能有一个直接父类。
- 多继承:一个子类可以有多个直接父类。
AA类继承于BB类,BB类继承于CC类,CC类继承于DD类,。。。,从而就形成了“继承链”。
–> 此处BB类,CC类和DD类都是AA类的“父类”,只有BB类属于AA类的“直接父类”。
java语言中,一个子类只能有一个直接父类,但是一个父类可以有多个直接子类。
如果一个类没有显式地使用extends关键字,则该类就默认继承于”java.lang.Object”类。
–> 所有的java类都可以使用object类提供的方法。【最终继承的都是object类】
方法重写(方法复写,override)
方法重写的引入
- eg:智能机是对功能机做的扩展,也就是应该让“智能机类”继承于“功能机类”,也就意味着“父类”和“子类”中都有show()方法,从而就形成了“方法重写”。
什么是方法重写呢?
- 在子类中,我们定义一个和父类“几乎”一模一样的方法,这就形成了“方法重写”。
什么时候使用方法重写?
- 当父类提供的方法无法满足子类的需求,则在子类中就可以重写父类提供的方法,从而满足开发的需求。
父类的哪些方法子类不能重写?
- 父类的构造方法,子类不能重写。
- 父类的静态方法,子类不能重写。
- 父类私有的成员方法,子类不能重写。
方法重写的注意点
通过子类对象来调用重写方法,则默认调用的是子类重写的方法,而不是调用父类被重写的方法。
保证子类的某个方法肯定是重写方法,则可以在该方法声明之前添加“@Override”注解,从而保证该方法肯定是重写方法。
–> 如果某个方法声明之前添加了“@Override”注解,则该方法就必须是重写方法,否则就会编译错误。
在子类重写方法中,如果想要调用父类被重写的方法,则必须通过super关键字来调用(this和super使用类似)
方法重写的具体要求
==,子类重写方法的“方法名”和“形参列表”必须和父类被重写方法的“方法名”和“形参列表”相同。
–> 此处“形参列表”必须相同,指的是“形参个数”和“形参类型”必须相同,形参名字不同不影响。
“>=”,子类重写方法的修饰符权限必须大于等于父类被重写方法的修饰符权限【权限】。
–> 修饰符权限:public > protected > default > private
–> 注意:子类就不能重写父类采用了static或private来修饰的方法。
“<=”,子类重写方法的“返回值类型”必须小于等于父类被重写方法的“返回值类型”【辈分】。
–> 如果父类被重写方法的返回值类型为void、基本数据类型和String类型,则子类重写方法的返回值类型必须和父类被重写方法的返回值类型保持一致(==)。
–> 如果父类被重写方法的返回值类型为引用数据类型(排除String类型),则子类重写方法的返回值必须小于等于被重写方法的返回值类型。(<=,辈分)。
方法重载和方法重写的区别
整体区别
英文名字区别
方法重载:overload
方法重写:override
使用位置区别
方法重载:同一个类中使用。
方法重写:必须在继承体系中使用。
具体作用区别
方法重载:允许在同一类中定义多个同名的方法,从而避免了方法名被污染。
方法重写:父类提供的方法如果无法满足子类需求,则子类就可以重写父类提供的方法。
修饰符的区别
方法重载:修饰符不同,不构成方法重载。
方法重写:子类重写方法的“修饰符权限”必须大于等于父类被重写方法的“修饰符权限”【权限】。
返回值类型的区别
方法重载:返回值类型不同。不构成方法重载。
方法重写:子类重写方法的“返回值类型”必须小于等于父类被重写方法的“返回值类型”【辈分】。
方法名的区别
方法重载:方法名必须相同。
方法重写:方法名必须相同。
形参列表的区别
方法重载:形参个数不同 或 形参类型不同,形参名字不同不影响。
方法重写:形参个数 和 形参类型必须相同。
重写toString()方法(理解)
- 请问print()和println()方法的作用
- 通过输出语句,都能把输出的内容转化为字符串类型,然后把转化为字符串类型的结果输出到控制台。
super关键字(重点)
super关键字的概述
- 创建一个对象成功之后,则虚拟机就会动态地创建一个引用,该引用指向的就是“新创建出来的对象”,并且该引用的名字就是this。
- 创建一个子类对象成功之后,则虚拟机还会动态创建一个引用,该引用指向的就是“当前对象的直接父类对象”,并且该引用的名字就是super。
- 总结:this指的就是“当前对象”,super指的就是“当前对象的直接父类对象”。并且this可以单独使用,但是super不能单独使用。
super关键字的作用
- 强调:this和super指的都是“对象”,并且this和super使用场合是相同的(构造方法、成员方法和构造代码块)。
- 操作父类的成员变量,语法: super.父类成员变量名
- 调用父类的成员方法,语法:super.父类成员方法(实参列表);
- 调用父类的构造方法,语法:super(实参列表);
this和super的区别
- this的特点:先在当前类找,找不到再去父类找。
- super的特点:直接去父类找,而不会在当前类找。
super关键字的注意点
在子类重写方法中,如果想要调用父类被重写的方法,则必须通过super关键字来实现。
当局部变量,子类的成员变量和父类的成员变量同名的时候,则该如何去区分呢?
局部变量采用“就近原则”,子类成员变量通过“this”来操作,父类成员变量通过“super”来操作。
父类私有的成员变量,在子类中即使使用super关键字也无法操作,只能通过setter和getter方法来操作父类私有成员变量。
super(实参列表)的概述
- 在子类构造方法中,如果想要显式地调用父类的某个构造方法,则必须通过“super(实参列表)”来实现,从而实现了代码的复用。
- 在子类构造方法中,如果没有显式地调用别的构造方法,则默认就会调用父类的无参构造方法,也就是编译时会默认添加“super();”语句。
super(实参列表)的注意点
- “super(实参列表)”只能存在于构造方法中,并且必须在构造方法有效代码的第一行。
- 建议每个类都应该有自己的无参构造方法,避免在继承体系中子类找不到父类的无参构造方法。
this(实参列表)和super(实参列表)的区别
- this(实参列表)的特点:调用“当前类”的别的构造方法,并且必须在构造方法有效代码的第一行。
- super(实参列表)的特点:调用“父类”中的某个构造方法,并且必须在构造方法有效代码的第一行。
- 结论:因为“this(实参列表)”和“super(实参列表)”都必须在构造方法有效代码的第一行,因此构造方法中不允许同时存在“this(实参列表)”和“super(实参列表)”。
继承体系下,创建子类对象的步骤分析
- 第一步:加载类(先加载父类,后加载子类)
- 先执行父类的静态代码块,然后执行子类的静态代码块。
- 第二步:创建对象(先创建父类对象,后创建子类对象)
- 首先,执行父类的构造代码块,接着执行父类的构造方法。
- 然后,执行子类的构造代码块,接着执行子类的构造方法。
继承体系下,创建子类对象的内存分析
- 创建一个子类对象,则默认还会创建他的父类对象,并且创建的这些对象之间属于“包含”关系。
- 也就是说,子类对象中包含了父类对象,那么子类对象和父类对象的“首地址”肯定是相同的。
继承和组合
- 组合的引入
- 需求:有一台电脑,电脑中包含鼠标、键盘和CPU等。
- 实现:定义电脑类(Computer),然后再定义鼠标类(Mouse)、键盘类(KeyBoard)和CPU类(CPU),然后把鼠标、键盘和CPU作为电脑类的“成员变量”即可,这就形成了“组合”关系。
- 继承和组合
- 相同点
- 都能让类与类之间产生联系,都能实现代码的复用。
- 不同点
- 继承描述的是“is a”的关系,例如:Tiger is Animal, Student is a Person等等。
- 组合描述的是“has a”的关系,例如:Computer has a Mouse,Computer has a keyBoard等等。
- 相同点
final关键字的概述
- final关键字的含义
- 最终的、不可变的
- final关键字能修饰的内容?
- final关键字能修饰类、变量(局部变量、成员变量和静态变量)和方法(成员方法和静态方法),但是不能修饰构造方法和代码块。
final关键字的特点
使用final关键字修饰的类,
则该类就不能被继承。
- 使用final修饰的类,则改类肯定是一个子类,例如String、Math和System都采用了final修饰。
使用final关键字修饰的方法(成员方法和静态方法),则该方法就不能被重写。
- 如果某个成员方法不想被子类重写,则该方法就采用final来修饰即可,例如Object类中的很多方法都采用了final修饰。
使用final关键字修饰的变量(局部变量、成员变量和静态变量),则该变量就变为常量了。
- 常量名必须符合“标识符”的命名规则,必须符合“字母全部大写,多个单词之间以下划线连接”的命名规范。
- 使用final修饰的静态变量,要么做显式初始化,要么在静态代码块中初始化,否则就会编译错误。
- 使用final修饰的成员变量,要么做显式初始化,要么在构造代码块中初始化,要么在构造方法中初始化,否则就会编译错误。
使用final关键字,我们不能修饰构造方法、局部代码块、构造代码块和静态代码块。
final修饰引用数据类型变量的特点
- 引用数据类型的变量采用final修饰后,则该变量就变为常量了,因此常量保持的地址值不能更改,但是该常量指向堆内存中的成员变量值可以更改。
多态
使用多态的前提?
前提1:继承是实现多态的前提。
–> 让所有的动物类都继承于Animal类,也就是Animal类是所有动物类的父类!
前提2:子类必须重写父类方法。
–> 所有的动物类都重写了Animal类的eat()方法,毕竟每个动物吃的东西都不同。
前提3:父类引用指向子类对象。
–> Admin类中的feedAnimal()方法的形参为“Animal”类型,调用该方法时的实参为“Animal类的子类对象”,此处就用到了“父类引用指向子类对象”。
–> 调用feedAnimal()方法的代码为“admin.feedAnimal(new Dog());”,则实现赋值给形参的操作就等效于:Animal animal = new Dog();
使用多态的场合
场合一:方法的形参为父类类型,则实参就可以是该父类的任意子类对象。
–> 例如:管理员给动物们喂食的案例
场合二:返回值类型为父类类型,则返回值就可以是该父类的任意子类对象。
–> 例如:简单工厂模式的案例
多态情况下,操作成员变量的特点
- 编译时:检查“编译时类型”,也就是检查编译时类型中是否有该成员变量。
- 运行时:检查“编译时类型”,也就是操作了编译时类型中的成员变量。
- 总结:多态情况下操作成员变量,则编译和运行都检查“编译时类型”。
abstract的引入
- 需求:在教师职业中,有讲师和助教两个工种,他们都具备工作的能力。
- 实现:定义讲师类(Teacher)和助教类(Assistant),然后分别提供work()的方法。
- 问题:讲师类和助教类都有work()方法,也就是讲师类和助教类都有相同的代码,因此我们需要实现代码的复用。
- 解决:使用“继承”来实现。定义一个员工类(Employee),并且给员工类提供work()方法,然后让讲师类和助教类继承于员工类,并重写员工类中的work()方法。
- 问题1:世界上没有任何一个工种就叫做员工,因此员工类不应该被实例化!
- –> 使用“抽象类”来解决,也就是把员工类设置为抽象类即可。
- 问题2:为了避免讲师和助教偷懒,因为要求讲师类和助教类必须重写员工类的work()方法!
- –> 使用“抽象方法”来解决,也就是把员工类的work()方法设置为抽象方法。
抽象类
什么是抽象类
- 使用abstract关键字修饰的类,则我们就称之为“抽象类”。
抽象类的组成
- a)在抽象类中,依旧可以拥有成员变量和静态变量。
- b)在抽象类中,依旧可以拥有成员方法和静态方法,并且还可以有任意多个抽象方法。
- c)在抽象类中,依旧可以拥有构造方法,该构造方法用于给抽象类中的成员变量做指定初始化操作。
- d)在抽象类中,依旧可以拥有构造代码块和静态代码块。
- 总结:抽象类就是一个特殊的类,抽象类对比普通类新增了任意多个抽象方法。
抽象类的特点
a)抽象类不能被实例化,因为抽象类中包含了抽象方法。
b)抽象类肯定是一个父类,只有实现类“实现”了抽象类中的所有抽象方法,则该实现类才能被实例化,否则该实现类就是一个抽象类。
实现:子类重写父类的抽象方法,我们就称之为“实现”。
重写:子类重写父类的普通方法,我们就称之为“重写”。
c)抽象类可以作为方法的“形参类别”和“返回值类型”,也就是抽象类也可以实现多态。
d)实现类与抽象类之间属于“extends”的关系,并且属于“单继承”。
抽象方法
- 什么是抽象方法?
- 使用abstract关键字修饰的方法,我们就称之为“抽象方法”。
- 抽象方法的特点
- a)抽象方法只有方法声明,没有方法内部的具体实现,也就是没有方法体。
- b)抽象方法只能存在于“抽象类”和“接口”中,不能存在于“普通类”中。
- 关于abstract关键字的补充?
- a)请问abstract关键字和哪一个关键字是反义词???final
- b)请问abstract关键字不能和哪些关键字共存呢???final、private、static
接口
接口(interface)
- 接口的引入
- 需求:让飞机、炮弹、小鸟和超人进行飞行表演!
- 实现:定义飞机类(Plane)、炮弹类(Peng)、小鸟类(Bird)和超人类(SuperMan),然后为每个类提供showFly()的方法。
- 问题:飞机类、炮弹类、小鸟类和超人类都有showFly()方法,也就是这些类中有相同的代码,那么我们就需要实现代码的复用,如何实现?
- 解决:使用“继承”来解决。定义一个Flyable类,然后给Flyable类提供showFly()的方法,接着让飞机类、炮弹类、小鸟类和超人类“继承”于Flyable类,并重写Flyable类中的showFly()方法。
- 问题:继承描述的是“is a”的关系,也就是描述“相同体系”的基本行为,此处飞机、炮弹、小鸟和超人属于不同体系,因此使用继承不合适
- 解决:使用“接口”来解决。定义一个Flyable接口,然后给Flyable接口提供showFly()方法,接着让飞机类、炮弹类、小鸟类和超人类“实现”于Flyable接口,并实现Flyable接口中的showFly()方法。
- 总结:接口描述的是“is like a”的关系,也就是描述“不同体系”的相同行为,此处飞机、炮弹、小鸟和超人属于不同体系,因此使用接口很合适。
接口的概述
接口的定义
- 明确:接口使用interface关键字来修饰,并且interface和class属于平级的,因此interface和class不能共存!
接口的组成
a)接口中的属性,默认全部是“全局静态常量”,也就是默认使用了“public static final”来修饰。
b)接口中的方法,默认全部是“全局抽象方法”,也就是默认使用了“public abstract”来修饰。
在JDK1.8之后,接口中还新增了“全局静态方法”和“default修饰的全局默认方法”。
c)在接口中,不允许存在构造方法,因为接口中都没有成员变量,因此就无需存在构造方法。
d)在接口中,不允许存在静态代码块和构造代码块。
接口的特点
- a)接口不能被实例化,因为接口中存在抽象方法,并且接口中没有构造方法。
- b)接口可以作为方法的“形参类型”和“返回值类型”,也就是接口能够实现多态。
- c)接口与接口之间属于“extends”的关系,并且接口还属于“多继承”。
- d)抽象方法只能存在于“抽象类”和“接口”中,不能存在于“普通类”中。
实现类的概述
实现类的定义
- 明确:实现类和接口之间属于“implements”的关系,而不是属于“extends”的关系。
实现类的特点
- a)实现类只有“实现”了接口中的所有抽象方法,则该实现类才能被实例化,否则该实现类就是一个抽象类。
- b)实现类可以先继承一个父类,然后再去实现多个接口,实现多个接口的操作我们就称之为“接口的多实现”。
抽象类和接口的总结
普通类、抽象类和接口的特点
- 接口的抽象程度最高,抽象类的抽象程度次之,普通类的抽象程度最低。
抽象类和接口的对比
相同点
- 都是向上提取的结果,因此都不能被实例化。
- 都是向上提取的结果,因此都包含了抽象方法。
不同点
接口与接口之间属于“extends”的关系,并且属于“多继承”。
抽象类与抽象类之间属于“extends”的关系,并且属于“单继承”。
实现类与接口之间属于“implements”的关系,并且属于“多实现”。
实现类与抽象类之间属于“extends”的关系,并且属于“单继承”。
接口描述的是“is like a”的关系,也就是描述“不同体系”的相同行为。
抽象类描述的是“is a”的关系,也就是描述“相同体系”的基本行为。
接口中只有“全局静态常量”和“全局抽象方法”,JDK1.8之后新增了“全局静态方法”和“default修饰的全局默认方法”。
抽象类就是一个特殊类,抽象类对比普通类新增了任意多个抽象方法。
单继承和多继承的概述?
- 单继承:java、C#等等
- 解释:一个子类只能有一个直接父类,类似于一个儿子只有一个亲爹。
- 优势:简单、安全。
- 劣势:只能继承一个父类的内容,则子类功能不够强大。
- 多继承:C++
- 解释:一个子类可以有多个直接父类,类似于一个儿子可以有多个亲爹。
- 优势:可以继承多个父类的内容,则子类功能非常强大。
- 劣势:复杂、不安全。
接口的多实现的概述
- 需求:要求子类不但简单又安全,同时还要求子类功能非常强大,如何实现?
- 不但要集合单继承和多继承的优势,并且还要摒弃单继承和多继承的劣势。
- 实现:先让子类继承于某个父类,然后再让该子类实现多个接口,实现多个接口的操作就称之为“接口的多实现”。
- 通过以上的实现方式,我们就模拟了C++的多继承操作,并且还摒弃了C++多继承的劣势。
内部类的概述
什么是内部类
- 在OutClass类的内部,我们再定义InnerClass类就是内部类。
内部类的定义位置?
- 位置一:在类中,代码块或方法体的内部。
- 位置二:在类中,代码块和方法体的外部。
什么时候使用内部类?
- 描述一个事物的时候,我们发现该事物内部还有别的事物,此时就可以使用内部类来实现。
- 例如:描述小汽车的时候,我们发现小汽车内部还有发动机,此时的发动机就是一个内部类。
内部类的分类?
- 成员内部类(掌握)、静态内部类(掌握)、局部内部类(了解)和匿名内部类(重点)。
内部类编译的特点?
在OuterClass类的内部,我们再定义InnerClass类,此时我们对程序进行编译,则就会获得两个字节码文件
–> OuterClass.class 外部类的字节码文件,也就是OuterClass类的字节码文件
–> OuterClass$InnerClass.class 内部类的字节码文件,也就是InnerClass类的字节码文件
操作内部类的特点?
- 想要操作内部类,则必须通过外部类来实现,也就是内部类是依附于外部类的。
成员内部类(掌握)
明确:学习成员内部类的时候,我们建议把“成员内部类”当成“成员变量”来理解。
定义位置
- 在类中,代码块和方法体之外。
定义语法
[修饰符] class 外部类{ //成员内部类 [修饰符] class 内部类{ //内部类中的代码 } }
成员内部类的实例化方式?
- 情况一:在外部类的内部,我们实例化成员内部类对象(掌握)
- 情况二:在外部类的外部,我们实例化成员内部类对象。(了解)
静态内部类(掌握)
明确:学习静态内部类的时候,我们把“静态内部类”当成“静态变量”来理解。
定义位置
- 在类中,代码块和方法之外。
语法
[修饰符] class 外部类{ //静态内部类 [修饰符] static class 内部类{ //书写静态内部类的代码 } }注意事项
a)定义静态内部类的时候,我们可以使用private、protected、public、final和abstract来修饰,并且还必须使用static来修饰
b)在静态内部类中,我们不但能定义成员变量、成员方法、构造方法和构造代码块,并且还能定义静态变量、静态方法和静态代码块。
c)想要操作静态内部类,则直接通过外部类名来操作即可,因为静态内部类是依附于外部类的,此处联想“静态变量”来理解即可。
在外部类的成员位置,我们可以直接操作当前类中的静态内部类;在外部类的静态位置,我们可以直接操作当前类中的静态内部类。
d)在静态内部类中,我们可以直接操作外部类的静态变量和静态方法,但是不能直接操作外部类的成员变量和成员方法。
静态内部类是依附于外部类的,也就是只要外部类加载完毕,则就能操作当前类中静态内部类。
e)想要操作静态内部类中的静态变量和静态方法,则我们还可以通过以下方式来直接操作:
- 操作静态变量:外部类.静态内部类.静态变量名;
- 操作静态方法:外部类.静态内部类.静态方法名(实参列表);
静态内部类的实例化方式?
- 情况一:在外部类的内部,我们实例化静态内部类对象(掌握)
- 情况二:在外部类的外部,我们实例化静态内部类对象(了解)
成员内部类和静态内部类的总结
- 成员内部类:如果内部类需要依附于外部类对象,则该内部类就必须为成员内部类。
- 静态内部类:如果内部类只需依附于外部类即可,并且需要在该内部类中定义静态内容,则该内部类就必须定义为静态内部类。
局部内部类(了解)
明确:学习局部内部类,则我们把“局部内部类”当成“局部变量”来理解。
定义位置
- 在类中,代码块或方法体的内部。
注意事项
a)定义局部内部类的时候,我们不能使用private、protected、public和static修饰,但是可以使用final和abstract来修饰。
b)在局部内部类中,我们只能定义成员变量、成员方法、构造方法和构造代码块,但是不能定义静态变量、静态方法和静态代码块。
c)局部内部类只能在“当前作用域”中使用,不能在代码块或方法体之外使用,此处我们可以联想局部变量的“生命周期”来理解。
d)在局部内部类中,我们“肯定”能操作外部类的静态变量和静态方法,但是“未必”能操作外部类的成员变量和成员方法。
在局部内部类中,是否能操作外部类的成员变量和成员方法,关键是看该局部内部类在哪个位置中定义的。
e)在局部内部类中,想要操作外部的局部变量,则该局部变量必须采用final来修饰,从而保证数据的安全性。
在局部内部类中,如果操作了外部的局部变量,则该局部变量的生命周期就延长了,也就是该局部变量的生命周期和局部内部类对象的生命周期保持一致了。
补充:在JDK1.8之后,如果在局部内部类中使用了外部的局部变量,则该局部变量默认就会采用final来修饰,从而保证数据的安全性。
匿名内部类(重点)
匿名内部类的概述
- 匿名内部类本质就是一个“局部内部类”,也就是一个“没有名字”的局部内部类,也就是一个特殊的局部内部类。
匿名内部类的语法
[修饰符] class 外部类 { { // 位置一:创建一个继承于某个父类的局部内部类对象,该局部内部类没有名字。 // 第一步:定义了一个继承于某个父类的局部内部类,并且该局部内部类没有名字。 // 第二步:创建该局部内部类对象,也就是常见了一个没有名字的局部内部类对象。 new 父类名() { // 书写匿名内部类中的代码 }; } [修饰符] 返回值类型 方法名(形参列表) { // 位置二:创建一个实现于某个接口的局部内部类对象,该局部内部类没有名字。 // 第一步:定义一个实现于某个接口的局部内部类,并且该局部内部类没有名字 // 第二步:创建该局部内部类对象,也就是常见了一个没有名字的局部内部类对象 new 接口名() { // 书写匿名内部类中的代码 }; } }匿名内部类的注意点
- a)匿名内部类就是一个特殊的局部内部类,因此局部内部类的要求对于匿名内部类依旧生效。
- b)在匿名内部类中,我们不能定义构造方法,因为匿名内部类都没有类名,而构造方法名必须为类名。
- c)在匿名内部类中,我们不建议定义自己“特有”的成员变量和成员方法,因为这样不方便我们去操作。
- 注意:在匿名内部类中,我们一般用于重写父类或接口中的抽象方法。
包装类
包装类的引入
- 世界上没有任何一门语言是完全面向对象的,因为面向对象语言中都包含了“基本数据类型”,为了方便“基本数据类型”和“引用数据类型”之间的转换,因此就诞生了“包装类”。
包装类的概述?
明确:每一种基本数据类型都对应一个包装类,因此Java语言中提供的包装类至少有8种。
byte Byte short Short int Integer long Long float Float double Double char Character boolean Boolean //注意:除了int类型和char类型之外,其余基本数据类型对应的包装类名都是“首字母大写”即可。Number类的概述
java.lang.Number属于一个抽象类,所有的“数值型包装类”都属于Number的实现类,也就意味着所有的数值型包装类都能使用Number抽象类所提供的方法,并且Number抽象类常见的方法如下:
public byte byteValue() { ... } --> 把数值型包装类对象转化为byte类型 public short shortValue() { ... } --> 把数值型包装类对象转化为short类型 public abstract int intValue(); --> 把数值型包装类对象转化为int类型 public abstract long longValue(); --> 把数值型包装类对象转化为long类型 public abstract float floatValue(); --> 把数值型包装类对象转化为float类型 public abstract double doubleValue(); --> 把数值型包装类对象转化为double类型
包装类的作用
作为和基本数据类型对应的类型存在,方便涉及到对象的操作,如Object[]、集合等的操作。
包含每种基本数据类型的相关属性如最大值、最小值等,以及相关的操作方法(这些操作方法的作用是在基本数据类型、包装类对象、字符串之间提供相互之间的转化)。
public class Test01 { public static void main(String[] args) { System.out.println("int类型表示的最大值:" + Integer.MAX_VALUE); System.out.println("int类型表示的最小值:" + Integer.MIN_VALUE); System.out.println("byte类型表示的最大值:" + Byte.MAX_VALUE); System.out.println("byte类型表示的最小值:" + Byte.MIN_VALUE); /*// 问题:数组的定义???数组就是一个存储“相同数据类型”的“有序”集合(容器)。 // 涉及到的技术:向上转型+自动装箱 Object[] arr = {123, 3.14, true, 'a', "abc", new Test01()}; System.out.println(Arrays.toString(arr));*/ } }
基本数据类型和包装类之间的转换
包装类的底层
- 所谓的包装类,则底层中定义了一个对应基本数据类型的“私有常量”来保存数据,包装类其实就是对基本数据类型的数据执行封装的操作。
- 例如:在Integer包装类中,其底层定义了一个int类型的“私有常量”来保存数据,也就是Integer包装类就是对int类型数据执行的封装操作。
基本数据类型转化为包装类
方式一:通过构造方法来实现
public Integer(int value) { ... } //作用:把基本数据类型转化为包装类对象。 public Integer(String s) throws NumberFormatException { ... } //作用:把字符串的内容转化为包装类对象。 //注意:当字符串存储的内容和对应的基本数据类型的数据格式不匹配的时候,则就会抛出“数值格式化异常”方式二:通过valueOf()静态方法来实现
public static Integer valueOf(int i) { ... } //作用:把基本数据类型转化为包装类对象。 public static Integer valueOf(String s) throws NumberFormatException { ... } //作用:把字符串的内容转化为包装类对象。 //注意:当字符串存储的内容和对应的基本数据类型的数据格式不匹配的时候,则就会抛出“数值格式化异常”。注意事项
针对Character类型,字符串不能转化为Character类型的包装类对象,因为Character类没有提供字符串参数的构造方法和字符串参数的valueOf()方法。
针对Boolean类型,只有字符串为“true”(不区分大小写)的时候,转化为包装对象的值才为true,否则一律都为false。
数值型的包装类中(不包含Character和Boolean),形参字符串的内容为必须为数值型,否则抛出NumberFormatException异常。
包装类转化为基本数据类型?
情况一:数值型包装类
–> 数值型包装类都是Number抽象类的实现类,因此数值型包装类使用Number抽象类提供的方法,我们就可以实现把“数值型包装类对象”转化为“数值型”。
情况二:非数值型包装类
–> 针对Character类型,我们可以使用Character类中提供的charValue()方法,从而将“Character对象”转化为对应的“char类型”。
–> 针对Boolean类型,我们可以使用Boolean类中提供的booleanValue()方法,从而将“Boolean对象”转化为对应的“boolean类型”。
自动装箱和自动拆箱(超级重点)
自动装箱和自动拆箱的概述
- 在JDK1.5之前,想要实现“基本数据类型”和“包装类”之间的转换,则必须通过调用包装类的方法来手动完成,此操作比较麻烦。
- 在JDK1.5之后,想要实现“基本数据类型”和“包装类”之间的转换,则我们可以通过自动装箱和自动拆箱来完成,此操作非常简单。
自动装箱机制的概述?
- 解释:当基本数据类型处于需要对象的环境中,则就会触发自动装箱机制,也就是自动会把基本数据类型转化为对应的包装类对象。
- 底层:当触发自动装箱机制的时候,则默认就会调用包装类的valueOf(xxx x)静态方法,从而将基本数据类型转化为包装类对象。
自动拆箱机制的概述?
- 解释:当包装类对象处于需要基本数据类型的环境中,则就会触发自动拆箱机制,也就是自动会把包装类对象转化为对应的基本数据类型。
- 底层:当触发自动拆箱机制的时候,则默认就会调用包装类的xxxValue()成员方法,从而将包装类对象转化为对应的基本数据类型。
- 例如:int num = new Integer(123); –底层–> int num = new Integer(123).intValue();
自动装箱的缓存问题?
- 解释:当“整数型”的数据取值范围在[-128, 127]之间的时候,如果触发了自动装箱机制,则就会从“缓存池”中取出一个包装类对象并返回,也就是不会创建新的包装类对象并返回。
- 当“整数型”的数据取值范围在[-128, 127]之外的时候,如果触发了自动装箱机制,则就会直接创建一个新的包装类对象并返回,也就是不会从缓存池中取出包装类对象来返回。
自动拆箱的空指针问题?
解释:当触发自动拆箱机制的时候,则默认就会调用包装类的xxxValue()成员方法,如果该包装对象为null,那么触发自动拆箱机制就会抛出空指针异常。
–> 例如:Integer integer = null; int num = integer; // 等效于: int num = integer.intValue();
基本数据类型和字符串之间的转换
字符串转化为基本数据类型(重要)
明确:使用包装类提供的parseXxx(String str)的静态方法来实现。
Byte static byte parseByte(String s) //将字符串参数解析为带符号的十进制byte 。 Short static short parseShort(String s) //将字符串参数解析为带符号的十进制short 。 Integer static int parseInt(String s) //将字符串参数解析为带符号的十进制int。 Long static long parseLong(String s) //将字符串参数解析为带符号的十进制long。 Float static float parseFloat(String s) //返回一个新 float值,该值被初始化为用指定字符串表示的值。 Double static double parseDouble(String s) //返回一个新 double值,该值被初始化为用指定字符串表示的值。 Boolean static boolean parseBoolean(String s) //将字符串参数解析为boolean值。注意事项:
- 1.不能把字符串转化为char类型,因为Character包装类中没有提供parseChar(String value)方法。
- 2.针对Boolean类型,只有字符串为“true”的时候(不区分大小写),转化为基本类型的值才为true,否则都为false。
- 3.整数型包装类,字符串中的内容必须是十进制整数;浮点型包装类中,字符串中的内容必须为十进制整数或浮点数,否则抛出NumberFormatException异常。
基本数据类型转化为字符串(了解)
明确:把基本数据类型转换为字符串,我们可以使用“+”连接符来实现,也可以使用包装类提供的方法来实现。
所有包装类 String toString() 返回对象的字符串表示形式。 Byte static String toString(byte b) 把byte类型转化为字符串返回。 Short static String toString(short s) 把short类型转化为字符串返回。 Integer static String toString(int i) 把int类型转化为字符串返回。 Long static String toString(long i) 把long类型转化为字符串返回。 Float static String toString(float f) 把float类型转化为字符串返回。 Double static String toString(double d) 把double类型转化为字符串返回。 Boolean static String toString(boolean b) 把boolean类型转化为字符串返回。 Character static String toString(char c) 把char类型转化为字符串返回。
String类讲解
字符串常量池的概述
- 加载类的时候,如果该类中有双引号创建的字符串,则就把该字符串在常量池中开辟存储空间并存储,并且常量池中存储的字符串都是唯一的。
- 执行程序的时候,如果遇到了双引号创建的字符串,则直接去常量池中取出该字符串并使用即可,也就是不会再次去创建一个新的字符串。
String类的概述
- 在字符串中,存储的是任意多个字符,这些字符以char类型的数组来存储的。在String类中,char类型的数组默认采用了final来修饰,也就意味着char类型的数组不能扩容,也就是字符串中存储的字符内容不可改变,因此我们称String为“不可变的Unicode编码序列”,简称“不可变字符串”。并且,String类还采用了final修饰,则意味着String类不能被继承。
String类的部分常用方法
length()方法
public int length() { ... } //作用:获得字符串的长度,也就是获得底层char类型数组的空间长度。charAt()方法
public char charAt(int index) { ... } //作用:根据索引获得字符串中的字符。 //注意:index取值范围在[0, 字符串长度-1]之间,超出范围则就会抛出StringIndexOutOfBoundsException异常indexOf()方法
- 明确:“从前往后”查找某个“字符”或“子串”在“主串”中的索引位置,如果查找的“字符”或“字串”不存在,则返回-1
int indexOf(int ch) //返回指定字符第一次出现在字符串内的索引。 int indexOf(int ch, int fromIndex) //返回指定字符第一次出现在字符串内的索引,以指定的索引开始搜索。 int indexOf(String str) //返回指定子字符串第一次出现在字符串内的索引。 int indexOf(String str, int fromIndex) //返回指定子串的第一次出现在字符串中的索引,从指定的索引开始搜索。 //注意:此处indexOf()方法的底层使用“字符串匹配算法”来实现,常见的字符串匹配算法有:BF算法和KMP算法。lastIndexOf()方法
- 明确:“从后往前”查找某个“字符”或“子串”在“主串”中的索引位置,如果查找的“字符”或“字串”不存在,则返回-1
int lastIndexOf(int ch) //返回指定字符最后一次出现在字符串内的索引。 int lastIndexOf(int ch, int fromIndex) //返回指定字符最后一次出现在字符串内的索引,以指定的索引开始搜索。 int lastIndexOf(String str) //返回指定子字符串最后一次出现在字符串内的索引。 int lastIndexOf(String str, int fromIndex) //返回指定子串的最后一次出现在字符串中的索引,从指定的索引开始搜索。startsWith()方法
public boolean startsWith(String prefix) { ... } // 作用:判断某个字符串是否以prefix开头。endsWith()方法
public boolean endsWith(String suffix) { ... } //作用:判断某个字符串是否以suffix结尾contains()方法
public boolean contains(CharSequence s) { ... } //作用:判断字符串中是否包含某个子串(开头、中间和结尾) //注意:此处CharSequence是一个接口,该接口的实现类有String、StringBuffer和StringBuilder字符串大小写转换
- 明确:字符串大小写转换,针对“英文字母”有效,针对“中文汉字”无效。
String toUpperCase() //返回一个新的字符串,该字符串中所有英文字符转换为大写字母。 String toLowerCase() //返回一个新的字符串,该字符串中所有英文字符转换为小写字母。 //注意:执行注册或登录操作的时候,就需要使用字符型大小写转换来校对验证码。忽略字符串前后空格
public String trim() //忽略字符串前后端的空格,中间的空格不用忽略字符串的截取操作
String substring(int beginIndex) //从beginIndex开始截取字符串,到字符串末尾结束。 // 注意:此处beginIndex的取值范围在[0, 字符串长度-1]之间。 String substring(int beginIndex, int endIndex) //从beginIndex开始截取字符串,到字符索引endIndex-1结束。 //注意:beginIndex的取值范围在[0, 字符串长度-1]之间,endIndex的取值范围在[0, 字符串长度]之间,并且endIndex必须大于beginIndex字符串的替换操作
// 通过用newChar字符替换字符串中出现的所有oldChar字符,并返回替换后的新字符串。 String replace(char oldChar, char newChar) //将与字面目标序列匹配的字符串的每个子字符串替换为指定的字面替换序列。 String replace(CharSequence target, CharSequence replacement)字符串拼接的操作
- 明确:我们可以使用“+”连接符来实现字符串的评价操作,也可以使用String类提供的“String concat(String str)”方法来实现。
public class Test02 { public static void main(String[] args) { // 需求:完成字符串的拼接操作 String str1 = "hello" + "world"; System.out.println(str1); // 输出:helloworld String str2 = "hello".concat("world"); System.out.println(str2); // 输出:helloworldisEmpty方法
//作用:判断字符串是否为空,也就是判断底层的char类型数组空间长度是否为0 public boolean isEmpty() { ... }equals方法
boolean equals(Object anObject) //判断字符串内容是否相同,区分字母大小写。 boolean equalsIgnoreCase(String str) //判断字符串内容是否相同,忽略字母大小写。valueOf方法
String类提供了valueOf(xxx x) //这个静态方法,该方法用于将其他的数据类型转化为字符串。
StringBuffer类的概述
- StringBuffer类继承于AbstractStringBuilder抽象类,StringBuffer类底层维护者一个char类型的数组,并且该char类型的数组没有使用final修饰,也就意味着该char类型的数组可以自动扩容,也就是该char类型数组存储的元素可以改变,因此我们就称StringBuffer类为“可变的Unicode编码序列”,简称“可变字符串”。并且,StringBuffer类采用了final修饰,也就意味着StringBuffer不能被继承。
String类和StringBuffer类特点
相同点:
- a)底层都维护者一个char类型的数组,也就是存储的都是字符,因此都属于“字符串”。
- b)这个两个类都采用了final修饰,也就意味着String和StringBuffer都不能被继承。
不同点:
String类底层的char类型数组使用了final修饰,因此String类存储的字符内容不可改变,我们就称之为“不可变字符串”。
–> 通过String类提供的方法来操作字符串中的内容时,都不是直接基于char类型数组做的操作,那么都会返回一个新的字符串。
StringBuffer类底层的char类型数组没有使用final修饰,因此StringBuffer类存储的字符内容可以改变,我们就称之为“可变字符串”。
–> 通过StringBuffer类提供方法来操作字符串中的内容,都是直接基于char类型数组做的操作,因此就可以无需返回新的字符串。
StringBuffer类的构造方法
StringBuffer() //构造一个没有字符的字符串缓冲区,初始容量为16个字符(有用)。
StringBuffer(CharSequence seq) //构造一个包含与指定的相同字符的字符串缓冲区CharSequence 。
StringBuffer(int capacity) //构造一个没有字符的字符串缓冲区和指定的初始容量。
StringBuffer类的方法
明确:如果StringBuffer类提供方法的返回值类型为StringBuffer或AbstractStringBuilder,则该返回值就是“当前方法的调用者对象”。
添加方法
//作用:在可变字符串末尾添加内容。 public AbstractStringBuilder append(Type type) { ... } // 作用:在可变字符串索引为offset位置插入字符串内容。 public AbstractStringBuilder insert(int offset, Type type) { ... } //注意:此处offset的取值范围在[0, 可变字符串长度]之间,超出范围则就会抛出“字符串索引越界异常”。替换的方法
//作用:把可变字符串索引为index的字符替换为ch即可。 public synchronized void setCharAt(int index, char ch) { ... } // 注意:此处index的取值范围在[0, 可变字符串长度 - 1]之间,超出范围则就会抛出“字符串索引越界异常”。 //作用:把可变字符串索引为[start, end)之间的元素替换为str即可。 public synchronized StringBuffer replace(int start, int end, String str) { ... } //注意:此处start的取值范围[0, 可变字符串长度 - 1]之间,end的取值范围在[0, 可变字符串长度]之间,并且end必须大于start。删除的方法
//作用:删除可变字符串中索引为index的字符。 public synchronized StringBuffer deleteCharAt(int index) { ... } // 注意:此处index的取值范围在[0, 可变字符串长度 - 1]之间,超出范围则就会抛出“字符串索引越界异常”。 //作用:删除索引为[start, end)范围之间的元素。 public synchronized StringBuffer delete(int start, int end) { ... } //注意:此处start的取值范围[0, 可变字符串长度 - 1]之间,end的取值范围在[0, 可变字符串长度]之间,并且end必须大于start。查找的方法
charAt(int index) //返回 char在指定索引在这个序列值。 indexOf(String str) //返回指定子字符串第一次出现的字符串内的索引。 indexOf(String str, int fromIndex) //返回指定子串的第一次出现的字符串中的索引,从指定的索引开始。 lastIndexOf(String str) //返回指定子字符串最右边出现的字符串内的索引。 lastIndexOf(String str, int fromIndex) //返回指定子字符串最后一次出现的字符串中的索引,从指定的索引开始。反转的方法
public synchronized StringBuffer reverse() 把可变字符串中的内容进行反转操作操作字符串长度的方法
// 作用:获得可变字符串的长度 public synchronized int length() { ... } // 作用:修改可变字符串的长度。 public synchronized void setLength(int newLength) { ... } //注意:如果“设置的长度”大于“可变字符串的长度”,则默认做“扩容操作”。 //如果“设置的长度”小于“可变字符串的长度”,则默认做“剪切操作”。字符串截取的方法
substring(int start) //返回一个新的 String ,其中包含此字符序列中当前包含的字符的子序列。 substring(int start, int end) //返回一个新的 String ,其中包含此序列中当前包含的字符的子序列。转化为String类的方法
// 作用:把StringBuffer对象转化为String类型。 public synchronized String toString() { ... }
StringBuilder类的概述
- StringBuilder类继承于AbstractStringBuilder抽象类,StringBuilder类底层维护者一个char类型的数组,并且该char类型的数组没有使用final修饰,也就意味着该char类型的数组可以自动扩容,也就是StringBuilder类存储的字符内容可以改变,因此我们就称呼StringBuilder类为“可变的Unicode编码序列”,简称“可变字符串”。并且,StringBuilder类采用final修饰,也就意味着StringBuilder不能被继承。
StringBuffer类和StringBuilder类的特点
- 相同点
- a)底层都包含char类型的数组,并且该char类型的数组都没使用final修饰,因此都称之为“可变字符串”。
- b)这两个类都采用了final关键字来修饰,也就意味着StringBuffer类和StringBuilder类都不能被继承。
- c)都继承于AbstractStringBuilder抽象类,并且这两个类拥有的方法都相同,因此使用方法属于类似的。
- 不同点
- StringBuffer:线程安全的,会做线程同步检查,因此效率较低(不常用)。
- StringBuilder:线程不安全的,不会做线程同步检查,因此效率较高(常用)。
使用“+”连接符完成字符串拼接操作的底层分析(重点)
- 情况一:两个字符串都是常量时,使用“+”来完成拼接操作
- 底层:因为常量保存的内容不可改变,也就是编译时期就能确定常量的值,因此为了提高字符串的拼接效率,所以就在编译时期就完成了拼接操作。
- 情况二:其中一个为字符串变量时,使用“+”来完成拼接操作
- 底层:因为编译时期无法确定变量的值,因此其中一个为字符串变量的拼接操作,那么肯定不是在编译时期完成,而是在运行时期来完成的,并且实现步骤如下。
三种字符串的拼接效率(重点)
System.currentTimeMillis()方法的概述?
- 作用:获得“当前时间”距离1970年1月1日凌晨的毫秒数。
- –> 公式:1秒 = 1000毫秒
- 使用:计算完成某个功能所需要的耗时,则就可以使用该方法来实现。
- –> 耗时:结束时间 - 开始时间
三种字符串的拼接效率?
StringBuilder的拼接效率最高,StringBuffer的拼接效率次之,String的拼接效率最低。
注意:如果需要大量执行字符串的拼接操作,则建议使用StringBuilder类来完成拼接操作。
链式调用语法(了解)
理解:每个成员方法体中都返回this,也就是每个成员方法体中都返回该方法的调用者对象。
- 问题:在目前已经学习的类中,哪些类支持链式调用语法呢???
- 答案:StringBuilder和StringBuffer
properties类
properties的概述
- Properties类是属于集合,叫做属性集
- Properties类是Hashtable的子类,所以存储的数据也是kv格式
- Properties类中的key和value只能是String类型
- Properties 类是一个持久的属性集,Properties可保存在流中或从流中加载。
常用方法:
操作属性:
String getProperty(String key) 用指定的键在此属性列表中搜索属性。 String getProperty(String key, String defaultValue) 用指定的键在属性列表中搜索属性。 Object setProperty(String key, String value) 调用 Hashtable 的方法 put。持久化方法,将数据保存到文件中
void store(OutputStream out, String comments) 以适合使用 load(InputStream) 方法加载到 Properties 表中的格式,将此 Properties 表中的属性列表(键和元素对)写入输出流。 void store(Writer writer, String comments) 以适合使用 load(Reader) 方法的格式,将此 Properties 表中的属性列表(键和元素对)写入输出字符。读取持久化的数据
void load(InputStream inStream) 从输入流中读取属性列表(键和元素对)。 void load(Reader reader) 按简单的面向行的格式从输入字符流中读取属性列表(键和元素对)。练习
public class Demo01 { public static void main(String[] args) throws IOException { // 创建属性集对象 Properties prop = new Properties(); // 设置属性 prop.setProperty("name","张三"); prop.setProperty("age","20"); prop.setProperty("sex","男"); /* * 将属性集持久化:(Writer writer, String comments) * 第二个参数是 文件的注释信息 * properties文件的注释格式是: # 注释文字 * * 属性集有字节的文件格式,扩展名是 .properties * 数据格式是 key=value * */ prop.store(new FileWriter("day23/user.properties"),"用户的信息"); // 读取properties文件的数据 Properties prop01 = new Properties(); // 将文件数据加到到Properties属性集中 prop01.load(new FileReader("day23/user.properties")); // 获取属性,如果属性不存在就返回null // String name = prop01.getProperty("name"); /* * getProperty(String key, String defaultValue) * 如果属性存在就返回对应的值;如果属性不存在就返回默认值defaultValue */ String name = prop01.getProperty("name1","不存在"); System.out.println(name); } }
日期时间类
使用方法
java.util.Date() 我们称为时间类,程序中我们通过new对象保存时间(单位为毫秒)
Date()类的构造方法:
public Date(){…}- 作用:获得保存“当前时间”的Date对象。
public Date(long date) {….}- 作用:获得保存“指定时间”的Date 对象(表示的就是“指定时间”距离1970年1月1日凌晨的毫秒数)
Date()类的成员方法:
- Long getTime();返回当前时间距离1970年1月1日凌晨的毫秒数。(获得时间)
- void setTime(long time);使用给指定的毫秒时间值设置现有的Date对象。(修改时间)
SimpleDateFormat 类的引入
- Java.text.SimpleDateFormat类属于DateFormat抽象类的实现类,开发中用来实现“Date对象”保存时间和“字符串”保存时间之间的相互转换。
测试代码
public class Test01 {
public static void main(String[] args) throws IOException {
//获取当前时间
Date date = new Date();
System.out.println(date);
SimpleDateFormat sf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒");
System.out.println(sf.format(date));
//将date对象保存的时间转换为calendar对象保存的时间
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
System.out.println(calendar);
//将calendar对象保存的时间转换为date对象保存的时间
Date date1 = calendar.getTime();
String s = sf.format(date1);
System.out.println(s);
}
}
时间日期转换格式
当出现y时,会将y替换成年。
当出现M时,会将M替换成月。
当出现d 时,会将d替换成日。
当出现h时,会将h替换成时(12小时制)。
当出现H时,会将H替换成时(24小时制)。
当出现m时,会将m替换成分。
当出现s 时,会将s替换成秒。
当出现s 时,会将s替换成毫秒。
当出现D时,获得当前时间是今年的第几天。
当出现w时,获得当前时间是今年的第几周。
当出现w时,获得当前时间是本月的第几周。
时间类的构造方法
SimpleDateFormat类的构造方法:
public SimpleDateFormat(String pattern){…}- 作用:实例化SimpleDateFormat对象,并且还能设置指定的格式规则
Public SimpleDateFormat类的成员方法:(重点方法)
public final String format(Date date){…}- 作用:把Date对象保存的时间转换为字符串保存时间。
public Date parse(String source) throws ParseException{…}- 作用:把字符串保存的时间转换为Date对象保存的时间
时间日期的其他常用类
Calendar类(日历类)
- Java,util.Calendar类,通过Calendar可以表示年、月、日、是、分、秒的一个具体时间,而且还提供了日期相关的计算功能。
Calendar类的实例化???
- Calendar类是一个抽象类,无法实例化,而是调用Calendar类的“Calendar getInstance()”静态方法来获得一个保存“当前时间”的
Calendar对象。
- Calendaer 类中提供的字段,默认全部是int类型的“全局静态常量”。
- calendar. YEAR获取年份
- calendar . MONTH获取月份,o表示1月,1表示2月,…,11表示12月
- calendar . DAY_OF_MONTH获取本月的第几天
- calendar . DAY_OF_YEAR获取本年的第几天
- calendar . HOUR_OF_DAY 小时,24小时制calendar. HOUR小时,12小时制
- calendar.MINUTE 获取分钟
- calendar.sECOND获取秒
- calendar.MILLISECOND获取毫秒
- calendar .DAY_OF_WEEK 获取星期几,1表示星期日,2表示星期一,…,7表示星期六
时间日期的计算及转换
计算的方法:
//根据字段来“增加”或“减少”数据(在“年或月..”增加或者减少多少)。 Public void add(int field,int amount){…}转换方法:
明确:开放中,经常设计到Date对象保存时间和Calendar对象保存时间之间的相互转换。
Public final void setTime(Date date){…} //作用:把Date对象保存时间转换为calendar对象保存的时间
枚举(enum)
枚举语法:
[修饰符] enum 枚举名{ 枚举值1,枚举值2,枚举值3,….. }使用语法:枚举名.枚举值
注意:在switch选择结构中,我们使用“枚举值”的时候必须省略“枚举名”。
枚举的底层?
在Java中枚举本质上就是一个被final修饰的类,并且继承了Java.long.Enum抽象类
类型的枚举中的所有枚举值,默认都是类型的全局静态常量。对枚举进行反编译,发现枚举中还提供了values()的全局静态方法,调用该方法就能返回枚举中的所有枚举值(用数组来存储)。
常用的API
System的常用方法
数组拷贝:static void arraycopy(object src,int srcPos,object dest,int destPos,int length)
输出当前时间的毫秒数:static long currentTimeMillis();
终止当前程序,退出Java虚拟机:static void exit(int s);(当s等于0时退出)
String类的常用方法
charAt(int index)
返回指定索引处的 char 值
concat(String str)
将指定字符串连接到此字符串的结尾
contains(CharSequence s)
判断是否包含次字符串:
copyValueOf(char[] data)
返回数组中表示次字符的字符串
copyValueOf(char[] data, int offset, int count)
返回数组中指定下标的字符串
endsWith(String suffix)
判断字符串是否以 指定字符串结尾
Math类的常用方法
Math.PI;
取圆周率:
Math.abs(基本数据类型 a);
取绝对值:
Math.cbrt(double a);
立方根:
Math.ceil(double a);
向上取整:
Math.floor(double a);
向下取整:
Math.max(int a,int b);
取两个数中的最大值:
Math.min(int a,int b);
取两个数中的最小值
Math.random();
[0,1)之间的随机数
Math.round(double a);
四舍五入:
Math.round(float a);
四舍五入:
(long)Math.fioor(数值+0.5)
注意:四舍五入的计算规则:
UUID类
- 表示通用的唯一标识符(UUID)类。表示一个128位的值
递归
- 就是方法体中直接或间接的调用方法自身
- 使用递归:
1.必须创建方法。
2.必须有结束条件,(不然就会形成死递归,导致栈溢出)。
3.构造函数不能使用递归。 - 递归的思想:
将一个大的问题拆分成几个小问题,所有小问题解决了,大问题就解决了。 - 注意:循环能够解决的问题递归一定能够解决,反之则不一定。
如果循环嵌套层次过多,则可以使用递归,但是递归效率比循环效率更低。
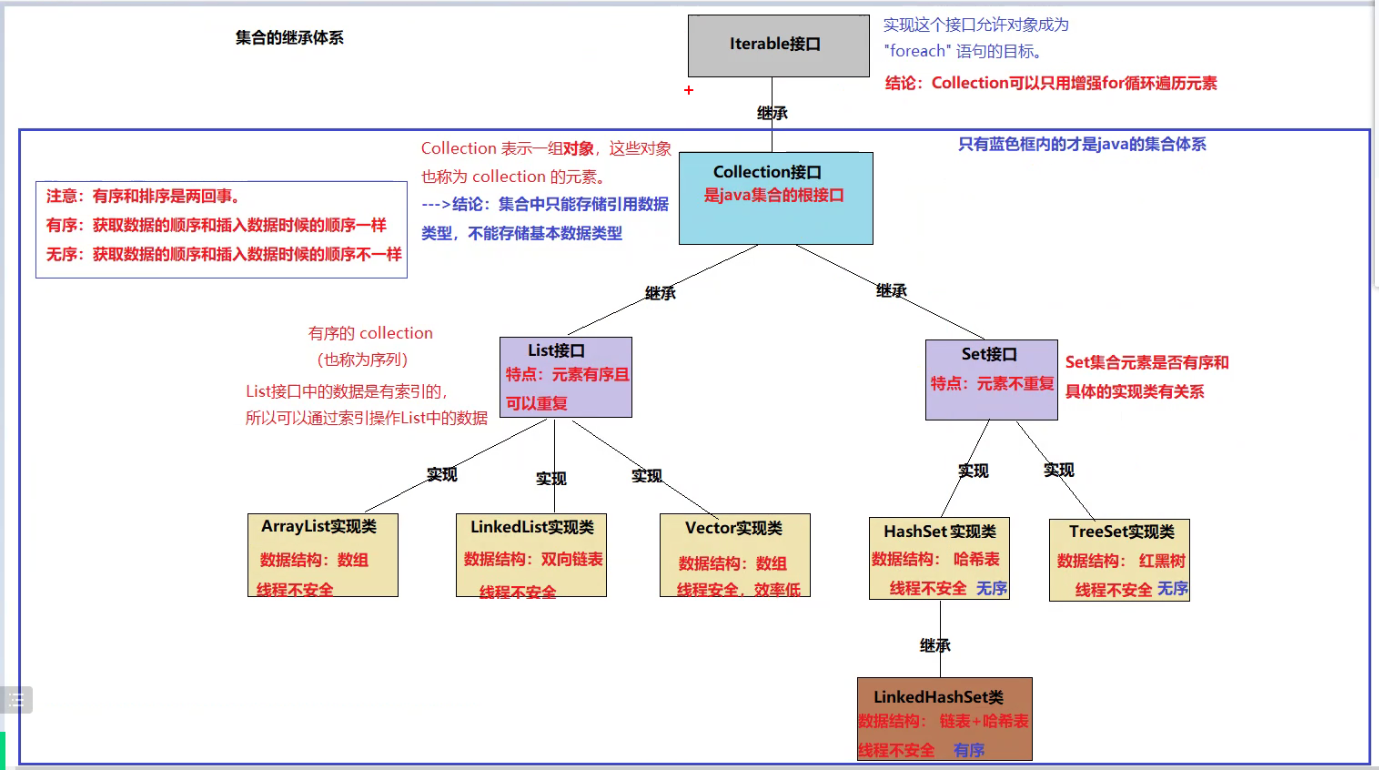
集合
集合Collection接口的继承结构图
LinkedList类
实现的接口:
- collection接口,List接口,Deque接口(双端队列)
链表之单向链表
一个节点由数据位和地址位组成,数据位就是存储元素,地址位就是下一个节点的地址。

链表之双向链表
一个节点由两个地址位和一个数据位,数据位存储元素,地址位一个地址位指向前一个节点的地址,一个指向下一个节点的地址。

链表的特点:
- 链表是由节点链接而成的
- 链表在内存中不是一段连续的内存空间,添加一个节点就在内存中新开一个空间存储节点
- 链表的增删效率高,查改的效率低。
- 非线程安全,安全性低,效率高。
Vector类
- 向量类
1. List的实现类
2. 底层数据结构:动态数组
3. 增删效率低,查改效率高
4. 线程安全的,安全性高,效率低(几乎不用)
泛型(genericity)
泛型:又叫参数化类型,就是应用数据类型作为参数了。(泛型也有形参和实参)
- 泛型的形参:仅仅表示这是一个泛型,没有具体的数据类型。(可以用 E T…)
- 泛型的实参:在创建对象时定义实参,约束集合的数据类型。
注意:只有引用数据类型才能作为泛型。
泛型的作用:约束集合中的元素的数据类型,将元素类型的检测从运行时提升到编译时。
泛型的方法:(该方法没什么实际运用,了解语法即可)
- 泛型方法的定义上一定有<泛型的形参>的方法才是泛型方法
泛型方法的语法格式:
修饰符 <泛型> 返回值类型 方法名(参数列表){}
泛型通配符:?(没什么鸟用,了解即可)
- 这里的?就是泛型通配符。
- 泛型通配符?:表示所有泛型实参,就是可以表示泛型所有的具体类型
:这里的E表示的是泛型所有的形参。
泛型通配符主要配合泛型的限定来使用
泛型的限定:
- 上限:<? extends T> 表示?只能是T类及其子类
- 下限:<? super T>表示?只能是T类及其父类
- 注意:T 表示一个类(自定义类也行)
泛型擦除:
- 源代码中使用的泛型,在经过编译后,代码中就看不大泛型,就是泛型擦除。
- (泛型擦除不是泛型丢失了,而是在编译后的字节码文件中使用单独的标识来存储泛型了)
set接口
- 是collection接口的子接口。
- 特点:元素不能重复,元素重复是否有序和实现类有关。
HashSet
- HsahSet是set接口的实现类。
- 元素不能重复
- 元素无序,特别是它不保证该顺序恒久不变。
- 底层的数据结构是HashMap<k,v>,HashMap的底层结构是哈希表
- 哈希表:也叫散列表,是根据关键码值(key)而直接进行访问的数据结构
- 哈希表是一个数组。
- 哈希表中的数据会产生哈希冲突(碰撞)
- 哈希冲突:不同的key,hashCode值一样,哈希表中的索引就一样,这就是哈西冲突。
LinedHashSet类
- 是HashSet的子类
- 底层为 链表+哈希表
- 特点:元素唯一且有序。
TreeSet类
TreeSet类是set接口的实现类
treeSet元素不重复
底层结构是TreeSetMap,treeMap的底层是红黑树
treeSet是根据元素进行排序
排序方法:
使用自然排序接口(Comparable)实现排序:
需要元素类实现该接口并且(添加泛型),才能实现排序功能
(设置排序规则:返回值< 0 倒序,返回值 = 0 元素相同,返回值 > 0 正序)
缺点:扩展性差,不易修改
使用比较器排序接口(Comparator)实现排序:
不需要元素类实现该接口,需要构造一个类实现该接口,在构造的类中写入比较条件。
优点:和比较的类解耦合,满足ocp原则,可以做多种排序要求。
注意:当利用无参构造创建对象时,调用的是自然排序。用有参构造new了一个比较器时,调用比较器排序。
Map<K,V>接口
HashMap实现类 , Hashtable实现类 , TreeMap实现类
map的结构继承图:
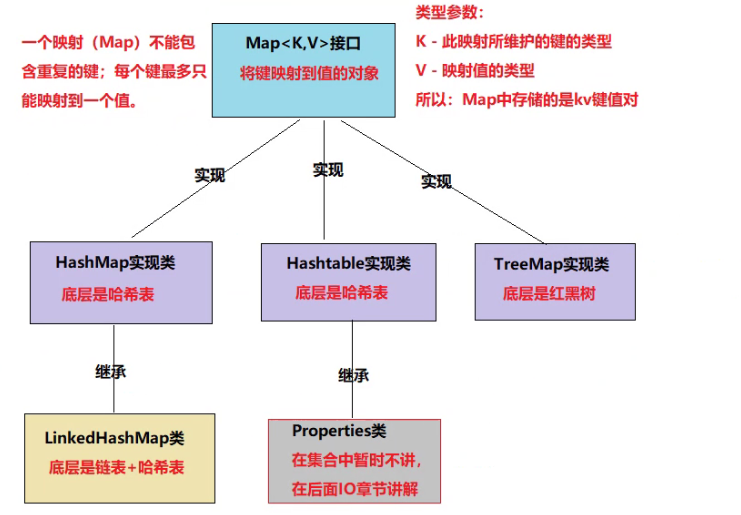
注意:根据以上的继承关系我们知道Map接口和Collection接口是没有关系的。
但是在开发中我们还是把Map叫做Map集合;因为Map接口也是java集合框架的成员。
此接口是Java Collections Framework的成员。
HashMap类
是Map接口的实现类
底层是数组+链表,1.8后加入了红黑树
线程不安全的,安全性低,效率高
允许使用null键,null值。
哈希表中的数组初始容量是16,当Map中的元素达到容量的0.75倍就会扩容。0.75是map的负载因子。这个数在时间和空间上都是相对最合适的
扩容:新容量=旧容量的2倍。
容量必须满足:<= 2的30次方。
LinkdHashMap类
- 保证了存储元素时的有序性。
Hashtable类
- 线程安全的
- hashtable保证线程安全是因为给每个方法都加上了锁,这就导致哈希表中就只有一个锁,若有多个线程争夺锁的时候,只要有一个线程得到锁,那么其他的线程就会阻塞等待,在效率上就会很低。
- 初始容量为11,负载因子0.75,
- 扩容后:新容量 = 旧容量 * 2 + 1
TreeMap类
- 是Map接口的实现类
- 底层是红黑树。
- 红黑树的数据结构是约束key的
- 可以对Map中的key排序
- 也有“自然排序”和“比较器排序”两种。
集合的部分方法扩展
集合的添加元素
Collections中的静态方法addAll方法可以将指定的多个元素全部加到集合中
Collections.addAll("集合名",添加的元素,添加的元素,.......);
集合的forEach遍历方法
在forEach中new一个Consumer接口,consumer接口也是函数表达式,里面的抽象方法是没有返回值,有一个参数。
这是lambda表达式:(lambda内容见下)
集合名.forEach((x) -> System.out.println(x));简写方法
集合名.forEach(System.out::println);
集合的排序
使用list.sort()方法中,传入Comparator接口类型的参数, Comparator接口是函数表达式,里面的抽象方法:返回值是int类型,有两个参数。
list.sort((x,y) -> x-y);lambda表达式:Comparator.comparing(元素对象::元素属性)(根据属性升序)(根据存储的元素,是基本数据类型,还是存储的对象,来确定是否调用方法的)
list.sort(Comparator.comparing(a -> a.方法)); list.sort(Comparator.comparing(对象::方法));
IO流
IO流的思维导图
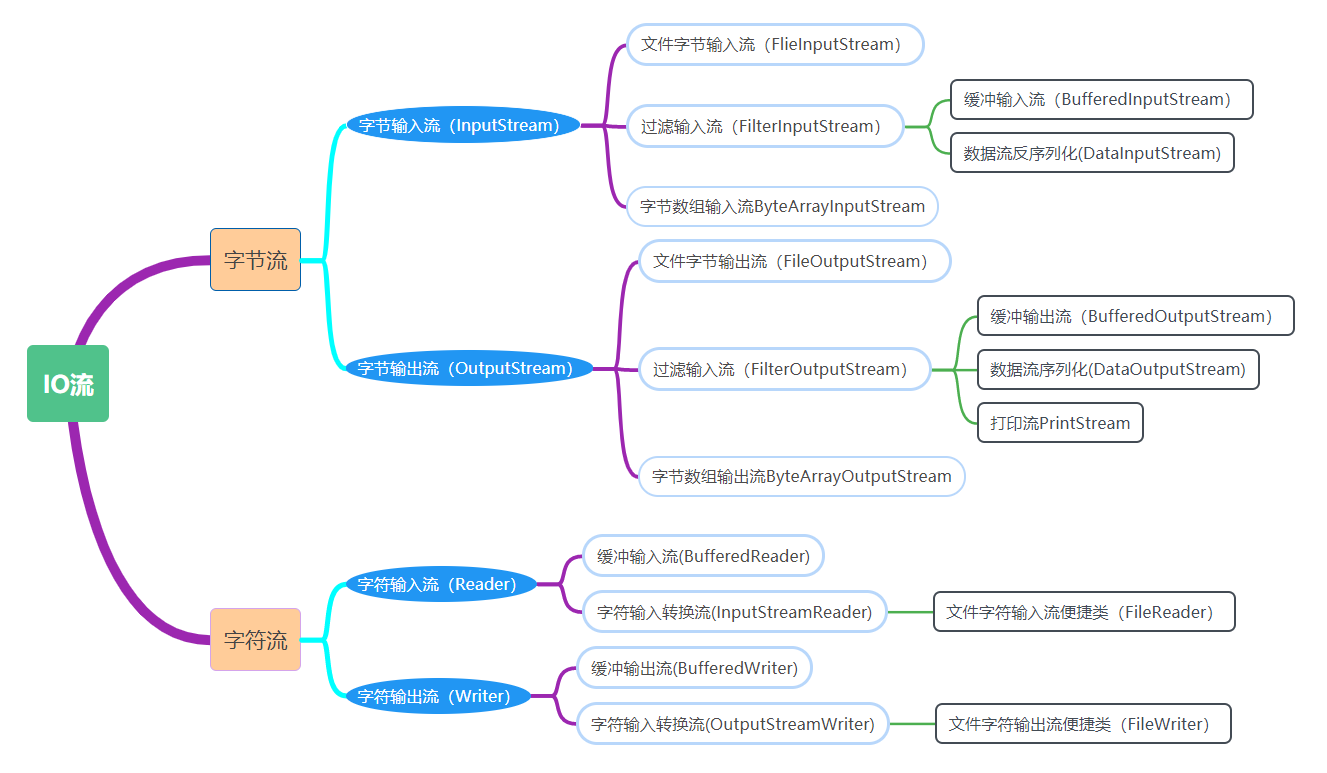
io流的引入
- 我们要将数据以文件的形式永久的保存到硬盘上,而要将数据写入文件中;或者从文件中读取数据,就需要使用io流
- IO流:
- io:输入输出
- 流:数据流,连续不断的数据
- IO流:
IO流的分类
根据流向的不同分为:
输入流:读数据,将数据读取到程序中
输出流:写数据,将程序中的数据写到文件中
根据操作数据的不同分为:
- 字节流:按照字节为单位写数据
- 字符流:按照字符为单位写数据
流根据不同功能分为:
- 节点流(普通流):真正读写数据的流。真正干活的。
- 处理流(包装流):是对节点流的封装,也就是在节点流的基础上增加心得功能。但是读写数据还是使用节点流
注意:
字节流是万能流,什么文件都可以操作,
字符流不是万能的,只有记事本打开不会乱码的文件,才可以用字符流操作。
四大基本抽象流
字节输入流(InputStream):按照字节为单位读数据
- 表示所有输出字节流的超类
字节输出流(outputstream) :按照字节为单位写数据
- 表示所有输入字节流的超类
字符输入流(Reader):按照字符为单位读数据
字符输出流(writer):按照字符为单位写数据
文件输入输出流
文件输入输出流是一种普通流,真正干活的。
文件输入流(FileInputStream)
用于读取硬盘中文件的数据。(以字节为单位读取)
public static void reader(){ FileInputStream fis = null; try { fis = new FileInputStream(new File("users.txt")); byte[] bytes = new byte[1024]; int len = 0; while ((len = fis.read(bytes)) != -1){ //存入数组中 fis.read(bytes, 0, len); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { if (fis != null) { try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } } }
文件便捷输入流(FileReader)
用于读取硬盘中文件的数据。(以字符为单位读取)
文件输出流(FileOutputStream)
- 用于向硬盘中的文件写入数据。(以字节为单位写入)
文件便捷输出流(FileWriter)
用于向硬盘中的文件写入数据。(以字符为单位写入)
public static void writer(String str){ FileWriter fw = null; try { //输出流,写入数据 fw = new FileWriter("users.txt"); fw.write(str); fw.flush(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { if (fw != null) { try { fw.close(); } catch (IOException e) { e.printStackTrace(); } } } }
缓冲流
缓冲流是一种处理流,在节点流的基础上增加了缓冲区。
字节缓冲输入流()BufferedInputStream)
- BufferedInputStream为另一个输入流添加一些功能,即华冲输入以及支持mark和reset方法的能力
字节缓冲输出流(BufferedOutputStream)
- 该类实现缓冲的输出流,通过设置这种输出流,应用程序就可以将各个字节写入底层输出流中,而不必针对每次字节写入调用底层系统。
标准输入输出流
计算机中的标准输入设备:键盘
标准输出设备:显示器
system类中的静态方法:
标准错误输出流(static Printstream err)
标准输入流(static Inputstream in)
- 作用于键盘
- 标准输出流(static Printstream out)
- 作用于显示器
打印流
- 打印流(PrintStream)
打印流是一种处理流,为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
数据流
数据流只有字节流,没有字符流
序列化(DataOutputStream)
将数据以乱码的方式写入,读需要使用反序列化(DataInputStream)来读取数据
public class Test03 { public static void main(String[] args) { DataOutputStream dos = null; try { dos = new DataOutputStream(new FileOutputStream("E:\\a.txt")); dos.writeInt(1); dos.writeInt(2); dos.writeChar('a'); dos.writeChar('b'); dos.flush(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally { if (dos != null) { try { dos.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
反序列化(DataInputStream)
读取序列化后的数据,读取时需要与写入时的数据类型顺序对应,否则会报错
public class Test04 { public static void main(String[] args) { DataInputStream dis = null; try { dis = new DataInputStream(new FileInputStream("E:\\a.txt")); System.out.println(dis.readInt()); System.out.println(dis.readInt()); System.out.println(dis.readChar()); System.out.println(dis.readChar()); System.out.println(dis.readByte()); } catch (Exception e) { e.printStackTrace(); } finally { if (dis != null) { try { dis.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
多线程
线程(Thread)
Java中使用Thread类表示线程。
注意:只有Thread类及其子类才能叫做线程
线程就是进程的执行路径。作用就是将程序指令交个CPU执行。一个进程至少需要一个线程。线程将指令交给CPU执行,是需要抢占CPU的时间片才能执行。CPU的一个核心执行一个线程。
多线程
- 一个程序有多个执行路径,那么这个程序就是多线程的程序。
创建线程
- 方法一:
- 创建Thread类的子类
- 子类重写run()方法
- 创建子类对象并成功
- 方法二:
- 创建Runnable接口的实现类
- 实现类重写run()方法
- 创建Thread时将实现类对象作为参数传递,启动Thread
- 方法一:
守护线程
void setDaemon(boolean on) ,当为true时用户线程变为守护线程。礼让线程
static void yield() (没什么用)
线程和进程的区别
- 进程是运行中的程序,是计算机中分配资源的最小单位。
- 线程是程序的执行路径,线程是在进程中的。线程是程序执行的最小单位。
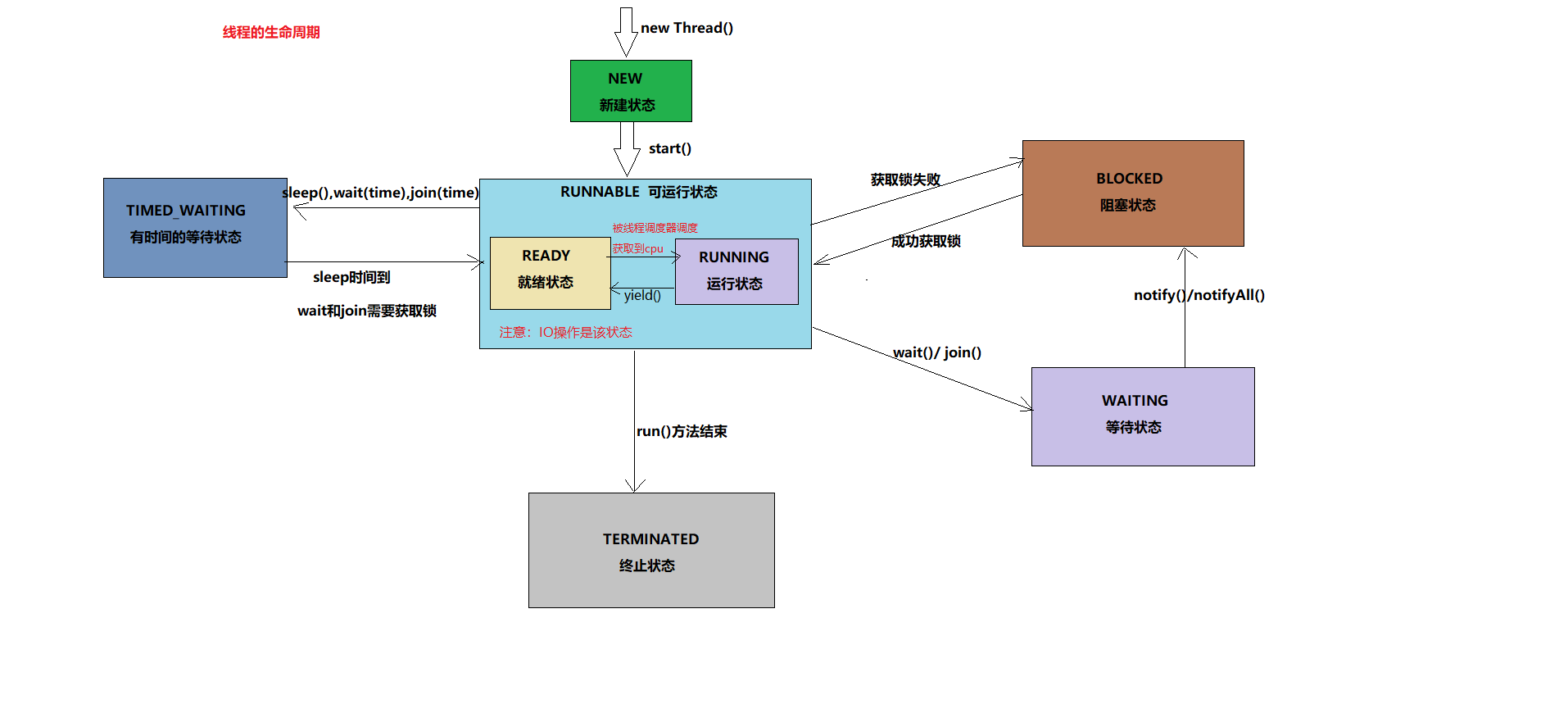
线程的生命周期
线程的状态:新建,就绪,运行,阻塞,死亡
线程的优先级
- 返回线程优先级:int getPriority();
- 设置线程优先级:void setPriority(int a)
- (最小优先级=1 <= a <= 最大优先级=10 ,默认优先级=5)
- 在cpu资源充足的情况下,设置优先级没有效果;在资源不足的情况下,优先级高的线程获取到资源的几率大一点。
中断线程
中断标记
Void interrupt() //给线程设置一个中断标记,不会中断线程。获取中断标记
Static boolean interrupted(); //(获取后会清除标记)
线程同步机制
同步代码块
synchronized(对象锁){ //操作共享数据的代码 }被synchronized修饰的代码具备有原子性。(要么不执行,要么执行结束)
对象锁:所有的多个线程是同一个锁。
同步方法
修饰符 synchronized 返回值 方法名(实参列表){ //共享修改的数据 }- 方法结束释放锁
- 建议方法中的代码全是共享的的数据
- 方法中的对象锁是:this
- 注意:静态的同步方法的对象锁是:字节码对象 (类名.class)
同步:(效率低)
- 多个线程执行时,线程是阻塞的,需要得到前一个线程的结果,另一个线程才能执行
异步:(效率高)
- 多个线程执行时,非阻塞的,线程之间是并发执行,不需要等待前面的结果。
Synchronized的可重入性:
- synchronized是一个不公平锁
- 公平锁:按照进入阻塞队列的顺序获取锁。
- 不公平锁:不管先后顺序,谁抢到就是谁的。
- synchronized是一个可重入锁
- 使用synchronized时,当一个线程得到一个=对象锁后,只要该线程还没有释放这个对象锁,再次请求此对象锁时可以再次获得该对象的锁。
- 可重入锁也支持在父子类继承的环境中,当存在父子类继承关系时,子类是完全可以通过“可重入锁”调用父类的同步方法。
- synchronized是一个不公平锁
线程之间通信机制
线程通信使用的是 “等待唤醒” 机制
等待:wait(); (会自动释放锁)
唤醒:notify();或者notifyAll(); (不会释放锁)
wait();notify();或者notifyAll();这几个方法必须出现在同步代码块中或者在同步方法中(用对象锁来调用)
notify();随机唤醒一个线程,notifyAll();将所有等待线程全部唤醒
Lock锁
public interface Lock- Lock、实现提供了比使用synchronized方法和语句可获得的更广泛的锁定操作。此实现允许更灵活的结构,可以具有差别很大的属性,可以支持多个相关的Condition对象。
- synchronized是关键字,我们不能修改。
- Lock的接口,接口中就是方法,接口的方法可以重写,还可以接收参数,所以比 synchronized更加灵活。
- Lock、实现提供了比使用synchronized方法和语句可获得的更广泛的锁定操作。此实现允许更灵活的结构,可以具有差别很大的属性,可以支持多个相关的Condition对象。
condition接口
- Condition将object监视器方法(wait、notify和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意Lock 实现组合使用,为每个对象提供多个等待 set (wait-set)。其中,Lock 替代了synchronized方法和语句的使用,condition替代了object监视器方法的使用。
- notify()/notifyAll()只能在配合synchronized使用
- condition接口的等待唤醒只能配合Lock使用
- condition接口的await/signal方法也必须编写在lock()和unlock()之间
单列模式
饿汉式
在类中就直接new对象
- 私有化构造方法
- 定义一个本类类型的静态变量,并私有化。
- 封装 一个get方法
public class DanLie01 { //不管是否调用,直接先new出对象 private static DanLie01 danLie01 = new DanLie01(); private DanLie01() { } public static DanLie01 getDanLie01() { return danLie01; } }懒汉式
用的时候才创建对象。
- 私有化构造方法
- 定义一个本类类型的静态变量,并私有化。(添加volatile关键字,解决指令重排)
- 封装一个静态方法(在方法中new对象)
- 添加同步代码块使线程安全
public class DanLie02 { //添加关键字volatile 解决指令重排问题 private volatile static DanLie02 danLie02; private DanLie02() { } public static DanLie02 setDanLie02(){ //这个if判断是为了减少同步代码块的调用,增加效率 if (danLie02 == null){ //使用同步代码块,防止多线程安全问题 synchronized (DanLie02.class) { //如果danLie02为空,表示还没有创建对象,所以就创建对象 //如果不为空,表示对象已创建,静态变量不能二次赋值,所以直接返回, // 保证对象的单列。 if (danLie02 == null) { danLie02 = new DanLie02(); } } } return danLie02; } }
定时器(Timer)
创建定时器类对象
自定义一个任务子类继承TimerTask
在任务类中写任务。
public class MyDeTimer { public static void main(String[] args) { //创建定时器对象 Timer timer = new Timer(); //创建定时器子类对象 MyTimer myTimer = new MyTimer(); //让myTimer类在两秒后执行。 timer.schedule(myTimer,2000); //让myTimer类在一秒后开始执行,每间隔两秒执行一次。 timer.schedule(myTimer,1000,2000); } } /** * 自定义定时器子类 */ class MyTimer extends TimerTask{ @Override public void run() { System.out.println("开始了"); } }
线程池(Exector)
线程池的工具类(Executors)
使用线程池创建单一线程:Executors . [**newSingleThreadExecutor**](mk:@MSITStore:C:\Users\ASUS\Desktop\JDK 1.6 API.chm::/java/util/concurrent/Executors.html#newSingleThreadExecutor())()
使用线程池创建多个固定可重复的线程:Executors . [**newFixedThreadPool**](mk:@MSITStore:C:\Users\ASUS\Desktop\JDK 1.6 API.chm::/java/util/concurrent/Executors.html#newFixedThreadPool(int))(int nThreads)
缓冲线程池:[**newCachedThreadPool**](mk:@MSITStore:C:\Users\ASUS\Desktop\JDK 1.6 API.chm::/java/util/concurrent/Executors.html#newCachedThreadPool())()
时间调度线程池:newS……
public class MyExecutor { public static void main(String[] args) { //创建多个固定可重复的线程 ExecutorService service = Executors.newFixedThreadPool(5); for (int i = 0; i < 5; i++) { service.submit(new Runnable() { @Override public void run() { System.out.println(Thread.currentThread().getName() + "开始"); } }); } //创建单一线程 ExecutorService service1 = Executors.newSingleThreadExecutor(); service1.submit(new Runnable() { @Override public void run() { System.out.println(Thread.currentThread().getName() + "单一线程执行"); } }); //创建缓冲线程 ExecutorService service2 = Executors.newCachedThreadPool(); service2.submit(new Runnable() { @Override public void run() { System.out.println("缓冲线程"); } }); } }
ThreadLocal类
该类提供了线程局部变量
每个线程都有自己的局部变量
ThreadLocal本身不存储数据,真正存储数据的是线程内部的ThreadLocalMap,ThreadLocal是Map的key值
执行过程图
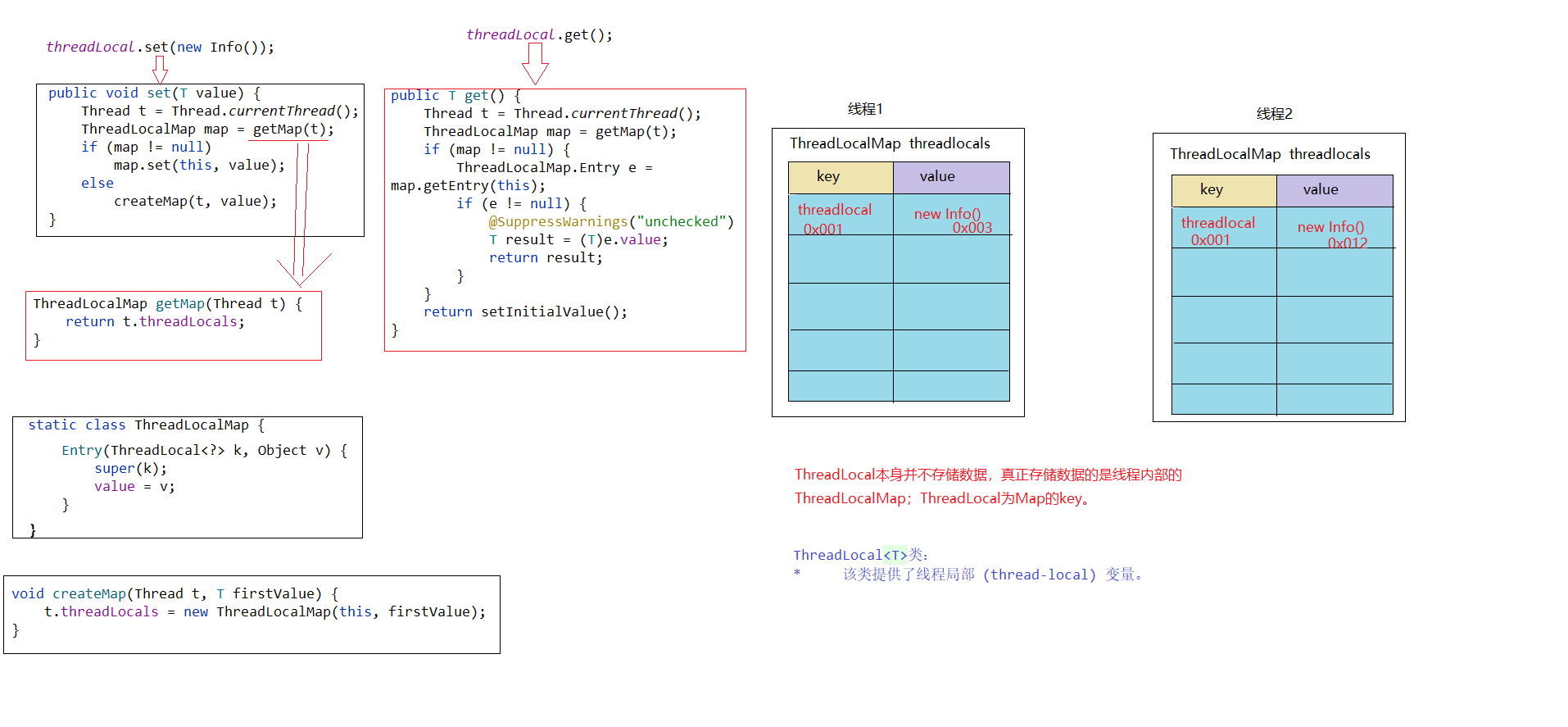
使用匿名内部类时
//自定义一个dog类 class Dog{} /** * ThreadLocal类 */ public class MyThreadLocal01 { /** * 创建时使用匿名内部类,重写initialValue方法,直接返回自定义类对象 * 这样输出方法中就可不用在new对象, */ private static ThreadLocallocal = new ThreadLocal (){ @Override protected Dog initialValue() { return new Dog(); } }; public static void main(String[] args) { //创建三个线程 for (int i = 0; i < 3; i++) { Thread thread = new Thread(new Runnable() { @Override public void run() { m1(); try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } m2(); } }); thread.start(); } } //定义两个方法 public static void m1(){ System.out.println(Thread.currentThread().getName() + "-->" + local.get() ); } public static void m2(){ System.out.println(Thread.currentThread().getName() + "-->" + local.get() ); } } 创建对象用set方法改变变量为局部变量
//自定义一个类 class Cat{} /** * ThreadLocal类 */ public class MyThreadLocal02 { //这个对象多线程无法起作用 //private static Cat cat = new Cat(); //创建一个ThreadLocal对象(泛型为cat)设置为静态,私有化 private static ThreadLocallocal = new ThreadLocal(); public static void main(String[] args) { //创建三个线程 for (int i = 0; i < 3; i++) { Thread t1 = new Thread(new Runnable() { @Override public void run() { //调用方法一 m1(); try { Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } m2(); } }); t1.start(); } } /** * 如果要保证两个方法输出的cat值是同一个,则不能new两个cat对象 * 如果值new一个静态的cat的对象,那么多线程输出就会被最后执行的一个线程覆盖,不能起作用 * 所以只能将cat对象用(ThreadLocal类)绑定cat对象将其设置成局部对象 */ //定义两个静态输出Cat的方法 public static void m1(){ //创建cat对象 Cat cat = new Cat(); //使用ThreadLocal的set方法绑定Cat对象 local.set(cat); //输出Cat System.out.println(Thread.currentThread().getName() + "->" + local.get()); } public static void m2(){ //输出Cat System.out.println(Thread.currentThread().getName() + "====>" + local.get()); } }
CountDownLatch倒计时锁
new一个对象出来,设置倒计时时长
调用conutDown方法一次可以减一。
public class MyCountDownLatch { public static void main(String[] args) { //创建一个倒计时锁对象 CountDownLatch latch = new CountDownLatch(1); //创建五个线程 for (int i = 0; i < 5; i++) { Thread t1 = new Thread(new Runnable() { @Override public void run() { //倒计时数字减一 //latch.countDown(); try { latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "已到位===="); } }); //启动线程 t1.start(); } System.out.println("主程序启动"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } latch.countDown(); } }
CyclicBarrier 循环栅栏
创建时设置线程数量
public class MyCyclicBarrier { public static void main(String[] args) { /** * 创建循环栅栏对象(设置线程个数) * 这个线程数量必须小于等于创建的线程数量,否则程序将陷入死等待 */ CyclicBarrier barrier = new CyclicBarrier(5); //使用线程池创建五个线程 ExecutorService service = Executors.newFixedThreadPool(5); for (int i = 0; i < 5; i++) { service.submit(new Runnable() { @Override public void run() { try { System.out.println(Thread.currentThread().getName() + "准备就绪"); Thread.sleep(1000); //当循环栅栏中的线程全部到达时,才会唤醒等待状态 barrier.await(); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "开始执行。。。"); } }); } } }
Semaphore:信号量
用来限制同时访问资源的线程数量
public class MySemaphore { public static void main(String[] args) { //创建信号量对象,设置同时访问的数量为4 Semaphore semaphore = new Semaphore(4); //创建是个线程,这里采用线程池的方式 ExecutorService service = Executors.newFixedThreadPool(10); for (int i = 0; i < 10; i++) { service.submit(new Runnable() { @Override public void run() { //使用信号量限定一次最多的执行次数 try { semaphore.acquire(); System.out.println(Thread.currentThread().getName() + "开始执行。。。"); } catch (InterruptedException e) { e.printStackTrace(); }finally { //执行结束后,让出信号位置 semaphore.release(); } System.out.println(Thread.currentThread().getName() + "停止执行!!"); } }); } } }
反射机制与注解
反射
根据字节码文件动态获取类信息
反射机制就是将类的各个组成部分(属性,方法 ,构造器 )封装为其他对象。
获取类信息
获取class对象的四种方法
- Calss.forName
- 类名.class (主要用于传参)
- 对象.getClass
- 包装类.TYPE
获取成员变量的字节码对象
类的指定公开成员变量 —-getField () 加一个 s 表示获取所有的
获取成员变量的变量名—-getName()
获取成员变量的返回值—–getTypt()
获取成员变量的修饰符—–getModifiers()
Field nameField = aClass.getField("name"); System.out.println(nameField); System.out.println(nameField.getName());//获取字段名 System.out.println(nameField.getType());//获取字段返回值 System.out.println(nameField.getModifiers());//获取字段的修饰符
使用构造方法创建对象
类的字节码文件对象.newInstance()
//直接用字节码对象创建对象(默认调用无参构造方法) Object obj = aClass.newInstance();构造方法对象.newInstance()
//通过无参构造对像创建对象 Object obj = constructor.newInstance();
获取构造方法的字节码对象
公开的构造方法:getConstructor()
非公开的构造方法:getDeclaredConstructor()
//获取无参构造对象 Constructor constructor = aClass.getConstructor(); //获取有参构造 Constructor constructor1 = aClass.getConstructor();注意:使用所有非公开的对象时,需要提前
使用:setAccessible(true)方法,来暴力避开 非公开的修饰符
获取方法的字节码对象
获取公开的方法:getmethod()
Method method = aClass1.getMethod("方法名");获取非公开的方法:getDeclaredMethod()
获取内部类的字节码对象
获取所有的内部类:getClasses
//通过外部类获取非静态内部类 Class[] classes = aClass.getClasses();判断是否是静态内部类
Modifier.isStatic(modifiers);注意:获取所有的内部类后,如果要判断是否是静态内部类 则
需要先获取修饰符对象,然后使用 :Modifier.isStatic静态方法判断
类加载器
扩展类加载器
启动类加载器
应用类加载器
Classpath:类路径,就是字节码文件所在的路径
- (src下面就是第一级包)第一级包就是类路径的开始。
那些内容可以加载进类路径:
- sre中的资源
- 被标记成resources root目录下的资源
- 第三方jar包
打包jar包的方法
- 选择左上角File –> Project Student…(资源包)
- 选择 Artifacts(构建) –>点击+号 —>点击JAR –>Form modules……
- 第一行选择你要打包的模块名 —>第二行 选择你模块中要运行的主类名。
- 第一个选项是将其抽取为一个目标的jar,
- 再下面是默认的文件保存位置
- 弹出提示框,可以修改文件的输出目录。
- 选择上方的Build,选择Build Artifacts,选择模块名,选择Build.
- 程序中的配置文件要放到resources 目录(resources自己创建的文件夹,注意要修改类型)
注解
注释:解释说明代码的—-程序员看的
注解:解释说明代码的——程序看的
注解语法格式:
元注解 Pbulic @interface 注解名{ 属性; }注解的属性
- 注解的本质是接口,注解是jdk1.5出现的,所以注解使用的是1.5时候的接口,1.5的接口只有常量值和抽象方法。也就是注解中的属性要么是常量值;要么是抽象方法来表示
- 结论:注解中的属性是抽象方法
- 方法名就是属性名
- 方法的返回值类型就是属性的数据类型。
注解中的属性的数据类型只能是:
- .基本数据类型
- String
- 枚举
- 注解
- Class
- 以上数据类型的数组
属性的使用细节:
- 属性可以有默认值;如果属性有默认值,那么使用注解的时候,该属性可以不用显示赋值
- 如果属性的名称叫做value,那么使用注解的时候,只单独使用value属性时,属性名可以省略不写,但是如果使用多个属性的时候value不能省略
- 注解中数组使用{}表示;使用注解的时候,如果{}中只有一个值时,{}可以省略不写
- 多个属性之间使用逗号分隔。
内置的元注解:
- @target : 标记定义的注解可以贴在那些地方
- @Retention : 表示注解可以保留到什么阶段。
注解有三个功能:
- 我们只能用一个就是用来“简化代码”。
lambda表达式和Stream流
lambda表达式
是用来简化函数式接口的匿名内部类代码的。
函数式接口:只有一个抽象方法的接口,使用@FunctionalInterface进行注解
语法:
(参数列表)-> { 函数体; [return [返回值];] }方法引用
- 当lambda表达式的函数体中只有一条语句且这条语句是调用其他方法完成功能,那么此时就可以使用方法引用简化lambda表达式
- 注意:函数体中的方法需要使用到参数列表中的参数
简化语法:
- 对象::实例方法
- 类名::静态方法
- 类名::实例方法
- 注意:当lambda表达式的函数体中只有一条语句且这条语句是调用其他方法完成功能,同时参数列表的第一个参数作为方法的调用者,其余参数作为方法的参数传递,此时可以使用 第三种方法 3.类名::实例方法
构造方法引用
- 当lambda表达式的函数体中只有一条语句,返回值为需要创建的对象类型,没有参数为无参构造,有参数为有参构造。
简化语法
- 类名::new
Stream流
Stream中的方法分为中间操作和终端操作
中间操作:方法的返回值是Stream,该方法就是中间操作
终端操作:方法的返回值不是stream,该方法就是终端操作
注意:终端操作不能写多个,想写多个只能重写多个流
顺序流:Stream(单线程的流)
并行流:parallelStream(多线程的流)
创建流的方法:
集合名.stream()//创建单线程流 集合名.parallelStream()//创建多线程流Stream的静态方法:of() iterate() generate()
of():直接添加元素在流中,返回一个流
iterate():无限迭代数据(limit可以设置迭代个数)(skip设置跳过几个数据)
generate():无限的生成数据。
stream流的常用方法:
遍历:forEach : 遍历流中的元素
过滤:filter:根据条件筛选出想要的元素
查找:
findFirst():找出集合中的第一个元素
findAny():配合并行流使用,找出任意一个线程的头元素。
匹配:
- anyMatch():只要有任意一个元素匹配条件则返回true
- allMatch():需要所有元素匹配条件则返回true
收集元素:collect()
收集器工具类:Collectors()
聚合:(max/min/count)
- Max:默认获取字符最长的元素
- Min:默认获取字符最短的的元素
- 注意:如果需要获取字节的长度,需要使用getBytes()方法转换
- Count:获取元素的个数
映射:(map/flatMap)
- map的特点:流进一个,流出一个(一对一的关系)
- flatMap的特点:进去一个,可以出来多个 (一对多的关系)
归约:(reduce)
归约:也称 缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
归约中有三个重载方法(下列例子中演示的为集合中元素求和)
只有一个参数的
/*Optionalreduce1 = stream.reduce((a, b) -> { System.out.println("a=" + a + " ,b=" + b); //流中执行的规则 a=2 ,b=4 a=6 ,b=6 a=12 ,b=7 a=19 ,b=8 a=27 ,b=9 36 return a + b; });*/ Optional reduce = stream.reduce((a, b) -> a + b); Optional reduce = stream.reduce((a, b) -> Integer.sum(a,b)); Optional reduce = stream.reduce(Integer::sum); 有两个参数的
//identity参数:恒等的,在流中给第一个变量赋上一个初始值 Integer reduce = stream.reduce(0, (a, b) -> a + b); Integer reduce = stream.reduce(10, (a, b) -> a + b);有三个参数的
- 注意:第三个参数,只有在并行流中才能执行,在顺序流中不会执行
// 第一个参数表示赋一个初始值 // 第二个参数accumulator表示 线程内部累加 // 第三个参数combiner表示 线程之间累加 // 线程每次都会获取identity进行操作 Streamstream = list.parallelStream(); Integer reduce = stream.reduce(10, (a, b) -> a + b, (x, y) -> x + y); Integer reduce = stream.reduce(10, Integer::sum, (x, y) -> x + y);
归集:(toList/toSet/toMap)
- toList:将收集器收集到的元素打包成List集合返回
- toSet:将收集器收集到的元素打包成 set集合返回
- toMap:将收集器收集到的元素打包成map集合返回
统计:(count/averaging)
注:以下全是收集器工具类中的方法
计数:counting()
平均值:averagingInt、averagingLong、averagingDouble
最值:maxBy、minBy
求和:summingInt、summingLong、summingDouble
统计以上所有:summarizingInt、summarizingLong、summarizingDouble
分组:(partitioningBy/groupungBy)
partitioningBy: 将元素通过某个条件分割为两个区
//根据工资将元素分为是否高于7000的两个区 Map<Boolean, List<Student>> collect = stream.collect(Collectors.partitioningBy(s -> s.getWages() > 7000));groupungBy: 根据条件将元素分割为多个区,可使用多个条件分割多次
//根据所在地将元素分隔成多个区 Map<String, List<Student>> collect = stream.collect(Collectors.groupingBy(s -> s.getAddress()));
拼接:joining:收集器里面的方法,元素拼接在一起
将所有的元素的名字拼接起来 String collect = stream.map(s -> s.getName()).collect(Collectors.joining("-"));自然排序:(sorted())
元素类需要实现comparable接口,重写方法
注意:实现接口时需要使用泛型。
Streamsorted = stream.sorted();
比较器排序:comparator
排序规则反转方法:reversed()
二次排序方法:thenComparing()
注意:使用二次排序前 必须使前一个条件使用lambda方式书写成:对象::方法
//自定义排序规则 Streamsorted1 = stream.sorted((a,b) -> b.getId() - a.getId()); Stream sorted1 = stream.sorted(Comparator.comparingInt(s -> s.getId())); Stream sorted1 = stream.sorted(Comparator.comparingInt(Student::getId).reversed()); //二次排序的方法 Stream sorted = stream.sorted(Comparator.comparingDouble(Student::getWages).reversed().thenComparingInt(Student::getId));
Stream流的静态方法:
提取:Stream.iterate() :定义初始值,取出什么值
提取多少个limit()
是否需要跳过多少个 skip()
//提取出3,4,5,6,7 System.out.println(Stream.iterate(1, a -> a + 1).skip(2).limit(5).collect(Collectors.toList())); //提取出3,4,5 System.out.println(Stream.iterate(1, a -> a + 1).limit(5).skip(2).collect(Collectors.toList()));
组合:Stream.concat() : 将两个流组合成一个流。
去除重复值:distinct()
//创建两个流 Streamstream = list.stream(); Stream stream1 = list1.stream(); //合并两个流,然后去除重复值,在返回成一个数组 List collect = Stream.concat(stream,stream1).distinct().collect(Collectors.toList());



